Auphonic Multitrack Processor
Auphonic Multitrack takes multiple parallel input audio tracks, analyzes and processes them individually as well as combined and creates the final mixdown automatically.
Leveling, dynamic range compression, gating, noise and hum reduction, crosstalk removal, ducking and filtering can be applied automatically according to the analysis of each track.
Loudness normalization and true peak limiting is used on the final mixdown.
Important:
Auphonic Multitrack does
not work on macOS >= Ventura anymore!
Most of our new algorithms use custom hardware, therefore it is unfortunately not possible for us to update the current desktop apps - please consider using our web service instead!
Features
Audio Algorithms
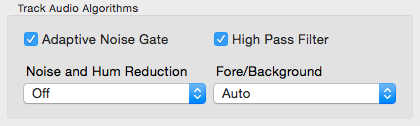
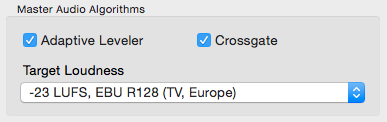
Auphonic Multitrack is most suitable for programs where dialog/speech is the most prominent sound: podcasts, radio, broadcast, lecture and conference recordings, film and videos, screencasts etc.
It is not built for music-only productions.
For more details about our multitrack algorithms please see Multitrack Post Production Algorithms!
The following algorithms are included in the Auphonic Multitrack Processor:
- Multitrack Adaptive Leveler
-
The Multitrack Adaptive Leveler analyzes the content of all tracks using machine learning techniques and
then balances any variations in loudness by:
- Classifying between music, background and speech segments
- Analysing which speaker is active in each track in order to produce a balanced loudness between each speaker
- Applying Dynamic range compression on speech tracks only whilst music segments are kept as natural as possible
- Correcting Loudness variations within each track that may be caused by changing microphone distance, different songs in music tracks etc.
- Isolating unwanted segments (noise, wind, breathing, silence etc.) and then excluding them from being amplified
- Adaptive Noise Gate
-
If audio is recorded with multiple microphones and all signals are mixed, the noise of all tracks will add up as well. The Adaptive Noise Gate decreases the volume of segments where a speaker is inactive, but does not change segments where a speaker is active.
All parameters of the gate (threshold, ratio, sustain, etc.) are set automatically according to the current context.
This results in much less noise in the final mixdown.
For details and audio examples see Multitrack Audio Example 2 and the other Multitrack Audio Examples.
- Crossgate: Crosstalk (Spill) Removal
-
When recording multiple people with multiple microphones in one room, the voice of speaker 1 will also be recorded in the microphone of speaker 2 and creates a crosstalk (spill), reverb or echo-like effect.
Our multitrack algorithms know exactly when and in which track a speaker is active and can therefore remove the same signal (crosstalk) from all other tracks. This results in a more direct signal and decreases ambience and reverb.
Listen to the details in Multitrack Audio Example 4 and the other Multitrack Audio Examples.
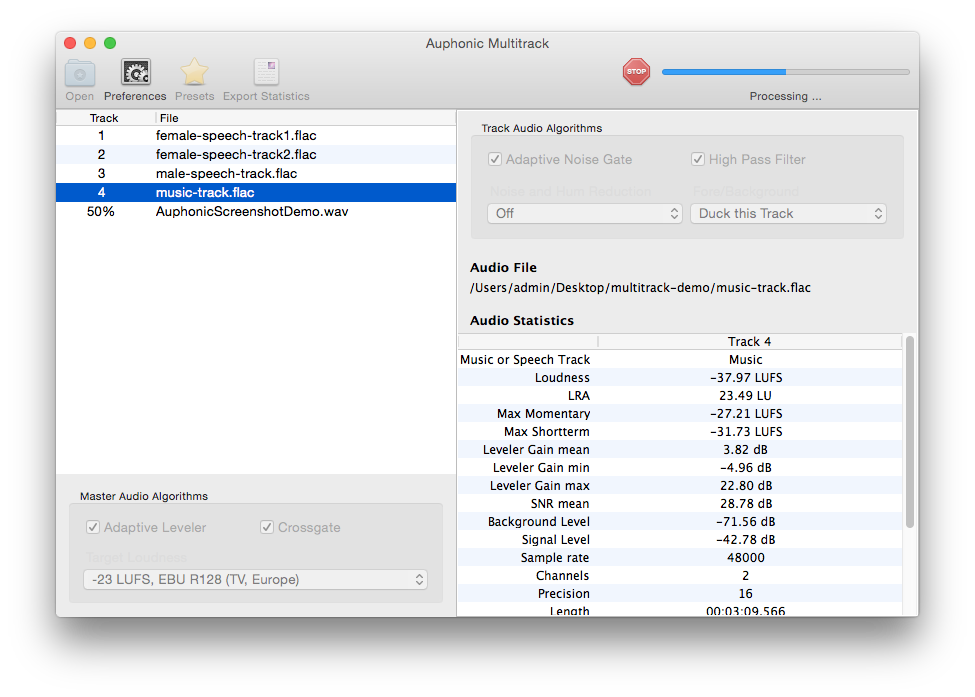
- Automatic Ducking and Foreground/Background Classifier
-
Auphonic automatically decides which parts of your track should be foreground or background:
Speech tracks will always be in foreground.
In music tracks, all segments (e.g. intros, songs, background music, etc.) are classified as background or foreground segments and mixed to the production accordingly.
If our classifiers do not work for your content, it is possible to force the track to be foreground or background.
We also support ducking to automatically reduce the level of a track if speakers in other tracks are active. This is useful for intros/outros, translated speech or for music segments, which should be softer if someone is speaking.
Listen to the Automatic Ducking Example and to the Fore/Background Audio Example.
- Multitrack Noise and Hum Reduction
-
Our Noise Reduction algorithms remove broadband background noise in audio signals with slowly varying backgrounds.
First each track is segmented in regions with different background noise characteristics, then a noise print is extracted in each region
and removed from the audio signal.
In automatic mode, a classifier decides if and how much noise reduction
is necessary.
The Hum Reduction algorithms identify power line hum and all its partials in each track. Afterwards the partials are removed as necessary with sharp filters.
For more details and audio examples see Noise Reduction and Multitrack Audio Examples.
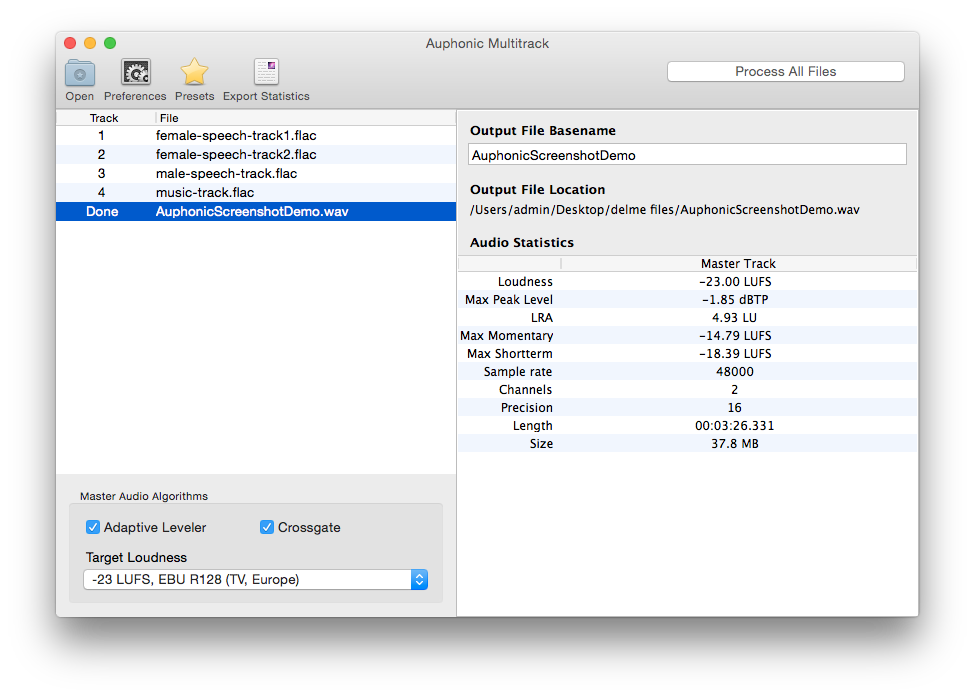
- Loudness Normalization with True Peak Limiter
-
Global Loudness Normalization calculates the loudness of the final mixdown and
applies a constant gain to reach a defined target level.
The loudness is calculated according to latest broadcast standards (ITU-R BS.1770)
and Auphonic supports loudness targets for television (EBU R128, ATSC A/85),
radio, podcasts, mobile and more.
A True Peak Limiter, with 4x oversampling to avoid intersample peaks, is used to limit the final output signal to the selected maximum true peak level and ensures compliance with the selected loudness target.
For more details see Global Loudness Normalization .
- High Pass Filter
-
An adaptive High Pass Filter cuts unwanted low frequencies,
depending on the context (speech, music or noise) of each track.
For more details see Multitrack Adaptive Filtering .
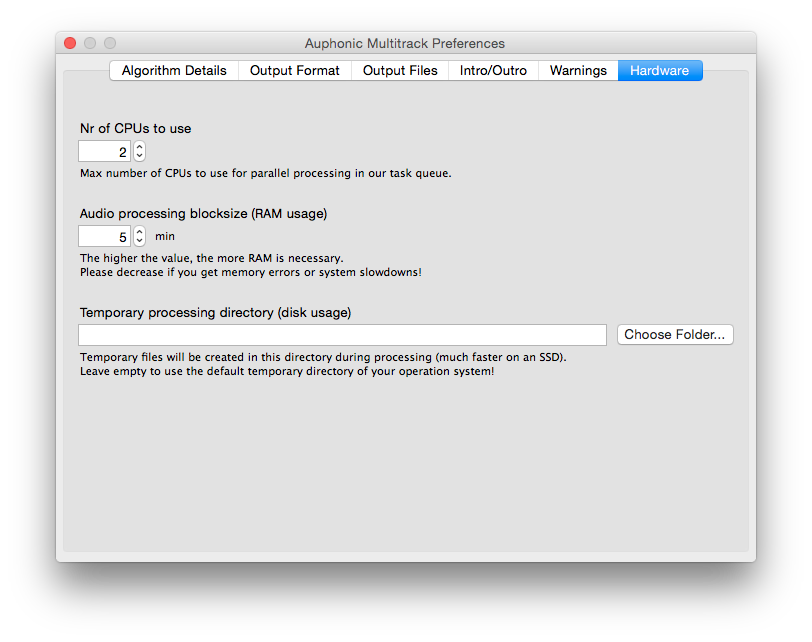
Parallel Processing of Multiple Tracks and Presets
The Auphonic Multitrack Processor includes a
Parallel Task Queue (multi core processing) with configurable CPU, RAM and disk usage.
Just drag and drop your tracks into the program window and the multitrack production will be
processed in parallel (with each track processed on its own core), using your current settings.
During processing, the progress is shown in the application.
All your current settings (audio algorithm parameters, parameters of individual tracks,
output file options, intros/outros, warnings, hardware settings, etc.)
can be saved as Presets.
Processing Statistics and Warnings
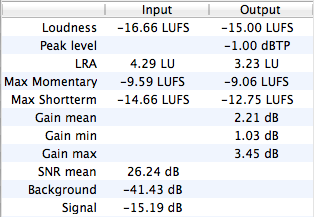
Audio Processing Statistics of the master and individual tracks
display details about what our algorithms are changing in your files.
They can be used to check compliance with
Loudness Standards
(Program Loudness, Maximum True Peak Level, LRA - see
EBU TECH 3341, Section 1
) and certain regulations for commercials (Max Momentary, Max Short-term Loudness - see Section 2.2).
It also shows how much our Adaptive Leveler changes your levels (Gain mean, min, max),
statistics about your input tracks (SNR, Background and Signal Level) and much more.
Statistics can be exported as files (manually or automatically)
in machine readable JSON, in YAML, or in a human readable text format.
The exact file format is the same as in our
Web Service and is documented
here.
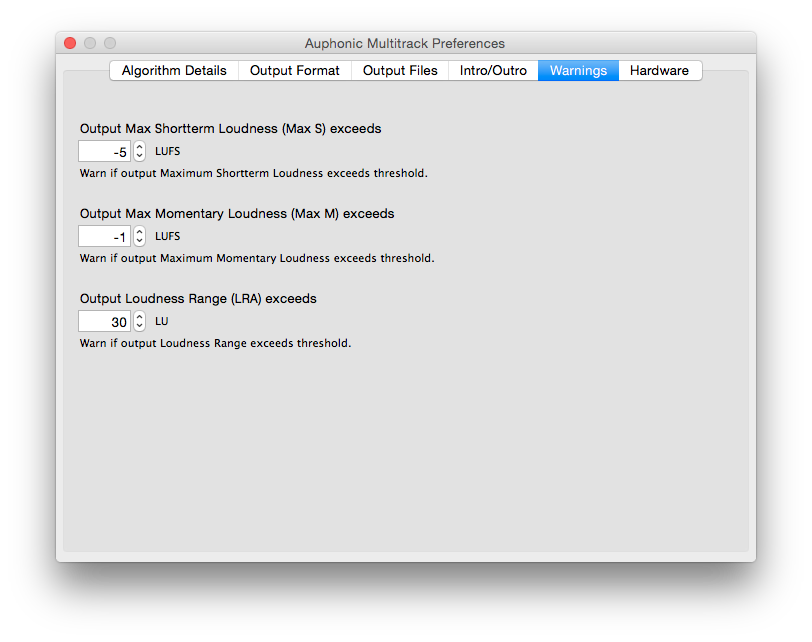
It is also possible to setup Warnings for quality control or as
alerts to manually check problematic segments in your audio:
for example, you don't want a MaxMomentary loudness >= -19 LUFS or
an Output Loudness Range >= 20 LU.
Warnings will be displayed in the application and are also exported
to processing statistics files.
Supported Input and Output File Formats
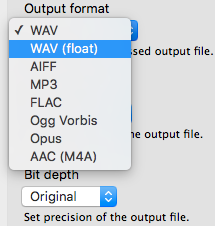 We support a wide range of input and a limited selection of output file formats.
Sample rate and bit depth conversions are using the high quality
resampling and dithering algorithms of
SoX.
We support a wide range of input and a limited selection of output file formats.
Sample rate and bit depth conversions are using the high quality
resampling and dithering algorithms of
SoX.
Please use lossless audio formats whenever possible.
It is also possible to export all individual, processed tracks as separate files in WAV, WAV (float) or FLAC format for further editing.
- Supported Input File Formats:
-
WAV, WAV (float), AIFF, FLAC, MP3, Ogg Vorbis, Opus
Mac OS X only: MP4/M4A/M4B, AAC, ALAC, CAF, AC3, MP2, 3GP - Supported Output File Formats:
-
WAV, WAV (float), AIFF, MP3 (via lame), FLAC, Ogg Vorbis, Opus
Mac OS X only: AAC (M4A)
Screenshots and Help
Please see Auphonic Multitrack Help for a descriptions of all available parameters and for further help.
Next Screenshot > < Previous Screenshot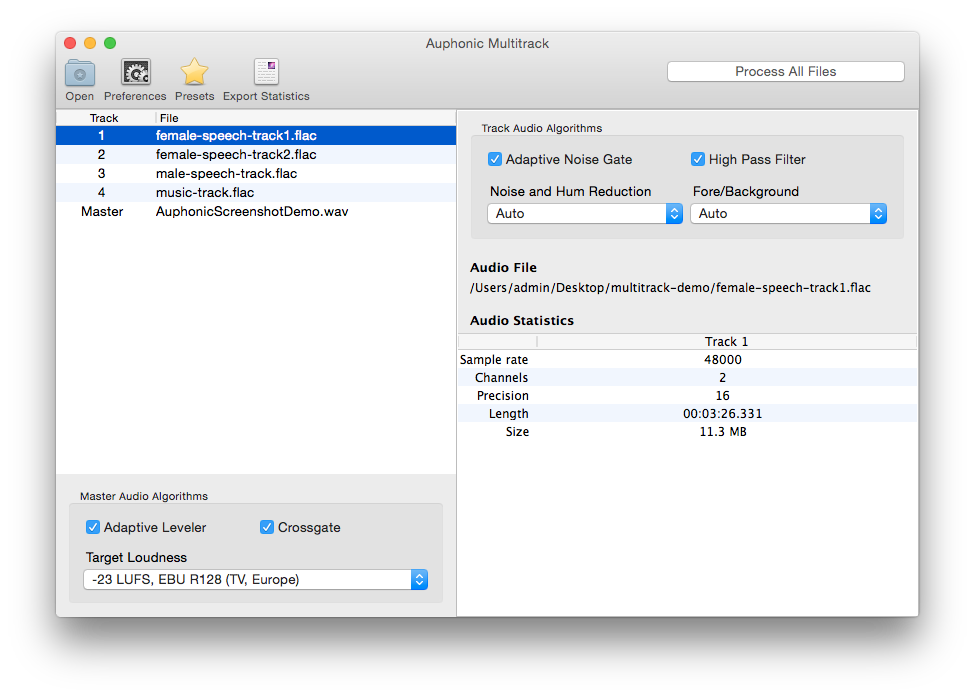
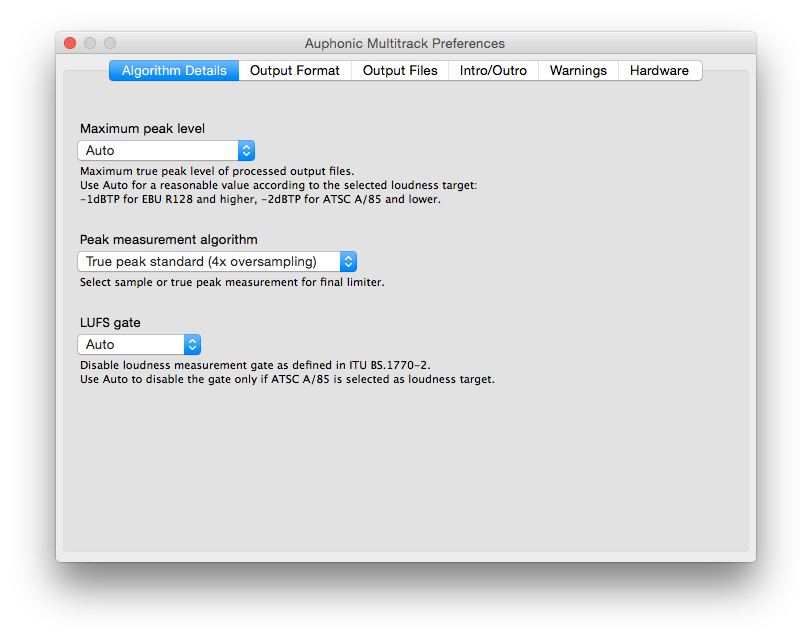
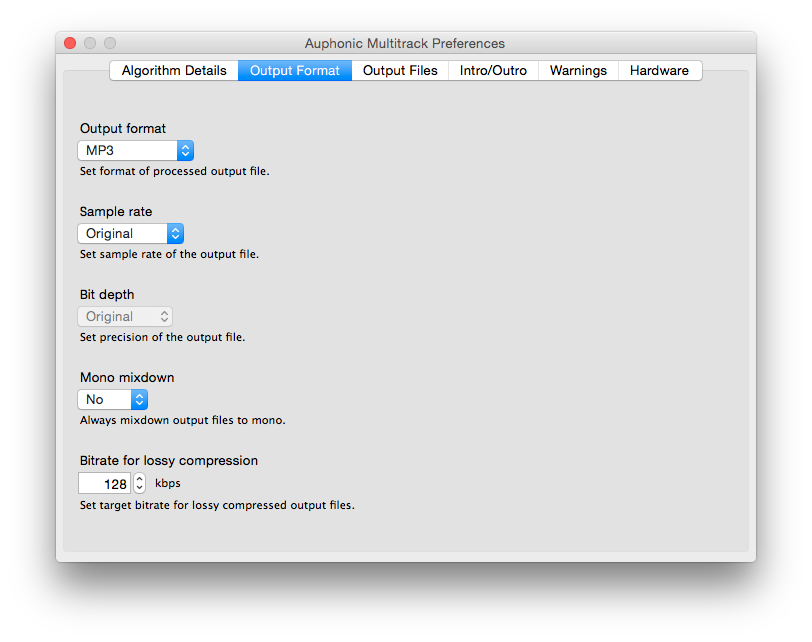
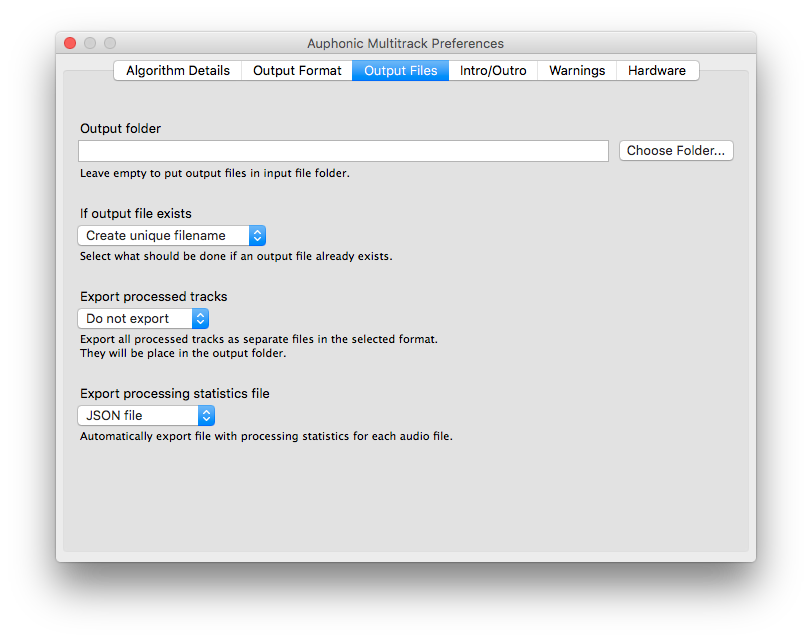
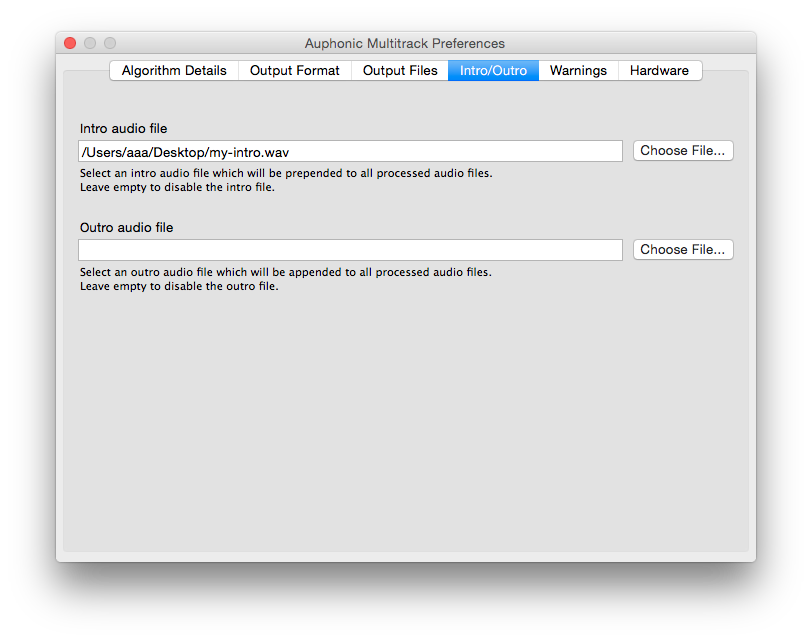
Next Screenshot > < Previous Screenshot
Multitrack Best Practice
Please read the following practical tips before using the Auphonic Multitrack Processor:
- What is Multitrack?
- The Auphonic Singletrack Post Production Algorithms
are optimized to process stereo or mono master audio files of a final mix.
However, many audio productions consist of multiple tracks: speaker tracks from multiple microphones,
music tracks, remote speakers via Skype, etc.
The Auphonic Multitrack Post Production Algorithms are built to use all separate tracks of a production, will process them individually as well as combined and will create the final mono/stereo mixdown automatically. - One Track is one File
- Each track must be opened as a separate file. We do not extract multiple tracks from a multichannel input file.
- Tracks start at the same time
- All tracks are mixed in parallel and must start at the same time: the length of each track might
be totally different, but they have to start at the same time.
NOTE for Audacity users: The multitrack export in Audacity is unfortunately a bit confusing: If your track does not start at the very beginning, you have to insert silence before it starts, otherwise the offset will be incorrect in the exported tracks! - Don't mix Music and Speech
- Don't mix music and speech parts in one track/file. Put all music segments into a separate track.
- One Speaker is one Track
- Please try to put each speaker into a separate track as well.
- Not built for Music-only Mixing
- Auphonic Multitrack is not built for music-only productions.
It is most suitable for programs, where dialogs or speech is the most prominent content: podcasts, radio, broadcast, lecture and conference recordings, film and videos, screencasts etc.
Take a look at our Multitrack Audio Examples to get a better idea what we can do. - Stereo Panorama is unchanged
- We do not change the stereo panorama of individual tracks – please adjust it in your
audio editor before using our multitrack algorithms.
Mono tracks are mixed in centered.
If all your input tracks are mono, the processed output file will be mono as well! - Keep Ambience
- If you want to keep the ambience of your recordings, try to deactivate the Adaptive Noise Gate, Crossgate and Speech Isolation or Dynamic Denoising.
- Export processed Input Tracks
- To export the processed version of each individual input track for further editing, select it already in the Multitrack Production Form by clicking Add Output File and selecting Individual Tracks in the Output Files section.
Once your multitrack production is done, you will find a downloadable .zip archive file containing the processed version of each individual track in .wav or .flac audio format, along with all the production result files. - How should I set the Fore/Background Parameter?
-
First, try leaving it at Auto. Then Auphonic automatically decides,
which parts of your track should be in foreground or background:
Speech tracks will always be in foreground. In music tracks, all segments (e.g. intros, songs, background music, etc.) are classified as background or foreground segments and mixed to the production accordingly.
See Fore/Background/Ducking Settings and Fore/Background Classifier Audio Example. - Set it to Duck this track, to automatically reduce the level of this track when speakers in other tracks are active. This is useful for intros/outros, translated speech or for music segments, which should be softer if someone is speaking. See Audio Example 5 / File 1.
- Set it to Background, if the whole track should be in background: background music, ambience recordings, just some background sounds, etc. See Audio Example 5 / File 2 to get an idea.
- If you set it to Foreground, all segments/clips of this track will be in foreground and will have a similar loudness as speech tracks. However, each segment/clip of the track (songs, intros, etc.) will be leveled individually, therefore all relative loudness differences between clips in this track will be lost.
- Use the option Unchanged (Foreground) if you do a lot of complex editing in your audio editor and don't want that Auphonic changes anything in this track. All relative volume changes are preserved in this mode and foreground/solo parts of this track will be as loud as (foreground) speech from other tracks.
-
First, try leaving it at Auto. Then Auphonic automatically decides,
which parts of your track should be in foreground or background:
Speech tracks will always be in foreground. In music tracks, all segments (e.g. intros, songs, background music, etc.) are classified as background or foreground segments and mixed to the production accordingly.
Contact
In case of any problems or questions, please don't hesitate to contact us at
support@auphonic.com.
We also build custom versions of our programs and algorithms on request!