Multitrack Best Practice
Please read the following practical tips before using the Auphonic Multitrack algorithms:
What is Multitrack?
The Auphonic Singletrack Post Production Algorithms are optimized to process stereo or mono master audio files of a final mix. However, many audio productions consist of multiple tracks: speaker tracks from multiple microphones, music tracks, remote speakers via Skype, etc.
The Auphonic Multitrack Post Production Algorithms are built to use all separate tracks of a production, will process them individually as well as combined and will create the final mono/stereo mixdown automatically.
One Track is one File
Each track must be opened as a separate file. We do not extract multiple tracks from a multichannel input file.
Tracks start at the same time
All tracks are mixed in parallel and must start at the same time: the length of each track might be totally different, but they have to start at the same time.
NOTE for Audacity users: The multitrack export in Audacity is unfortunately a bit confusing: If your track does not start at the very beginning, you have to insert silence before it starts, otherwise the offset will be incorrect in the exported tracks!
Don’t mix Music and Speech
Don’t mix music and speech parts in one track/file. Put all music segments into a separate track.
One Speaker is one Track
Please try to put each speaker into a separate track as well.
Not built for Music-only Mixing
Auphonic Multitrack is not built for music-only productions. It is most suitable for programs, where dialogs or speech is the most prominent content: podcasts, radio, broadcast, lecture and conference recordings, film and videos, screencasts etc.
Take a look at our Multitrack Audio Examples to get a better idea what we can do.
Stereo Panorama is unchanged
We do not change the stereo panorama of individual tracks – please adjust it in your audio editor before using our multitrack algorithms. Mono tracks are mixed in centered.
If all your input tracks are mono, the processed output file will be mono as well!
Keep Ambience
If you want to keep the ambience of your recordings, try to deactivate the Adaptive Noise Gate, Crossgate and Speech Isolation or Dynamic Denoising.
Export processed Input Tracks
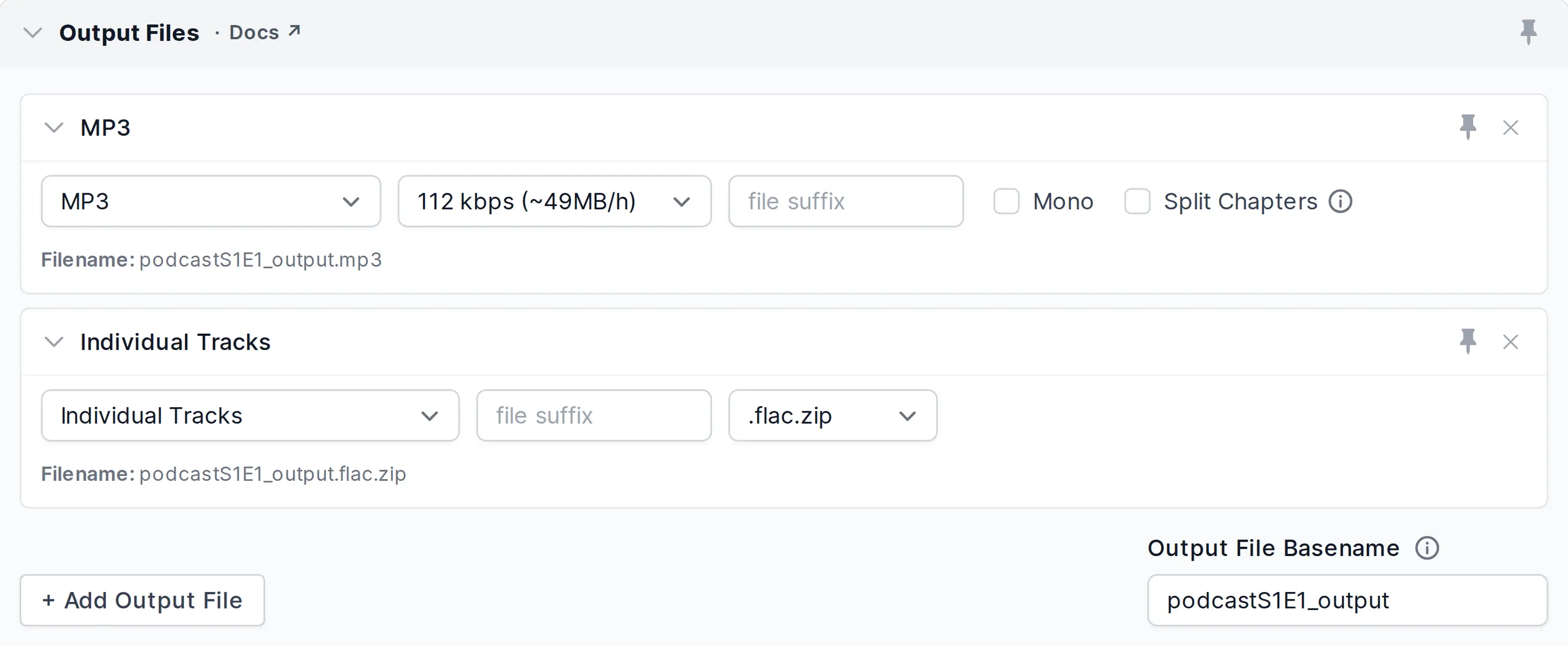
To export the processed version of each individual input track for further editing, select it already in the Multitrack Production Form by clicking Add Output File and selecting Individual Tracks in the Output Files section.
Once your multitrack production is done, you will find a downloadable .zip archive file containing the processed version of each individual track in .wav or .flac audio format, along with all the production result files.
How should I set the Fore/Background Parameter?
First, try leaving it at Auto. Then Auphonic automatically decides, which parts of your track should be in foreground or background: Speech tracks will always be in foreground. In music tracks, all segments (e.g. intros, songs, background music, etc.) are classified as background or foreground segments and mixed to the production accordingly.
See Fore/Background/Ducking Settings and Fore/Background Classifier Audio Example.Set it to Duck this track, to automatically reduce the level of this track when speakers in other tracks are active. This is useful for intros/outros, translated speech or for music segments, which should be softer if someone is speaking. See Audio Example 5 / File 1.
Set it to Background, if the whole track should be in background: background music, ambience recordings, just some background sounds, etc. See Audio Example 5 / File 2 to get an idea.
If you set it to Foreground, all segments/clips of this track will be in foreground and will have a similar loudness as speech tracks. However, each segment/clip of the track (songs, intros, etc.) will be leveled individually, therefore all relative loudness differences between clips in this track will be lost.
Use the option Unchanged (Foreground) if you do a lot of complex editing in your audio editor and don’t want that Auphonic changes anything in this track. All relative volume changes are preserved in this mode and foreground/solo parts of this track will be as loud as (foreground) speech from other tracks.