Automatic Speech Recognition, Shownotes and Chapters
Auphonic has built a layer on top of Automatic Speech Recognition Services:
Our classifiers generate metadata during the analysis of an audio signal (music segments, silence, multiple speakers, etc.) to divide the audio file into small and meaningful segments, which are then processed by the speech recognition engine. The speech recognition services support multiple languages and return text results for all audio segments.
The results from all segments are then combined, and meaningful timestamps, simple punctuation and structuring are added to the resulting text.
With enabled Automatic Shownotes and Chapters Feature, you can also get AI-generated summaries, tags and chapters from your audio, that automatically show up in your result files and in your audio files’ metadata.
This is especially interesting when used with our Multitrack Algorithms, where all speakers have been recorded on separate tracks:
In Multitrack Speech Recognition, all the tracks are processed by the speech recognition service individually, so there is no crosstalk or spill and the recognition is much more accurate, as it is only dealing with one speaker at a time.
This also means that we can show individual speaker names in the transcript output file and audio player because we know exactly who is saying what at any given time.
Automatic Speech Recognition (ASR) is most useful to make audio searchable: Although automatically generated transcripts won’t be perfect and might be difficult to read (spoken text is very different from written text), they are very valuable if you try to find a specific topic within a one hour audio file or the exact time of a quote in an audio archive.
We also include a complete Transcript Editor directly in our HTML output file, which displays word confidence values to instantly see which sections should be checked manually, supports direct audio playback, HTML/PDF/WebVTT export and allows you to share the editor with someone else for further editing.
Our WebVTT-based audio player with search in speech recognition transcripts and exact speaker names of a Multitrack Production.
How to use Speech Recognition within Auphonic
To activate speech recognition within Auphonic, you can either select our self-hosted Auphonic Whisper ASR service or one of the integrated external services in the section Speech Recognition and Automatic Shownotes when creating a new Production or Preset.
If you want to use an external service, you first have to connect your Auphonic account to an external speech recognition service at the External Services page. This connection process is very different depending on the speech recognition provider, therefore please visit our step-by-step tutorials.
Once that is done, you will have the option to choose whichever service you signed up for.
For our self-hosted service, you can skip the connection process and directly select Auphonic Whisper ASR as service:

The speech recognition transcripts will be combined with our other Audio Algorithms and generate different
Output Formats, depending on your selections.
Automatic Shownotes and Chapters
With this feature you can fully automate the time-consuming process of summarizing and structuring the content of your recording to find useful positions for chapter marks and to create shownotes. The autogenerated data is also stored in the metadata of your recording.
Shownotes usually contain short summaries of the main topics of your episode, links and other information, while inserted
chapter marks allow you to timestamp sections with different topics of a podcast or video.
They make your content more accessible and user-friendly, enabeling listeners to quickly navigate to specific sections of the episode
or find a previous episode to brush up on a particular topic.
Besides the obvious use of creating shownotes and chapters for podcasts, you can also use this feature to easily generate an abstract of your lecture recording, take the summary of your show as the starting point for a social media post, or choose your favorite chapter title as the podcast name.
How does it work?
When the Automatic Shownotes and Chapters feature is selected, the first step is speech transcription by either our internal Auphonic Whisper ASR or any integrated External ASR Service of your choice.
Some open source tools and ChatGPT will then summarize the ASR resulting text in different levels of detail, analyze the content to identify sections with the different topics discussed, and finally complete each section with timestamps for easy navigation.
Beginning with the generation of a Long Summary, the number of characters is further reduced for a Brief Summary and from the brief summary a Subtitle and some Keywords for the main topics are extracted.
Depending on the duration of the input audio or video file, the level of detail of the thematic sections is also slightly adjusted, resulting in a reasonable number of chapters for very short 5-minute audio files as well as for long 180-minute audio files.
Automatically Generate Data
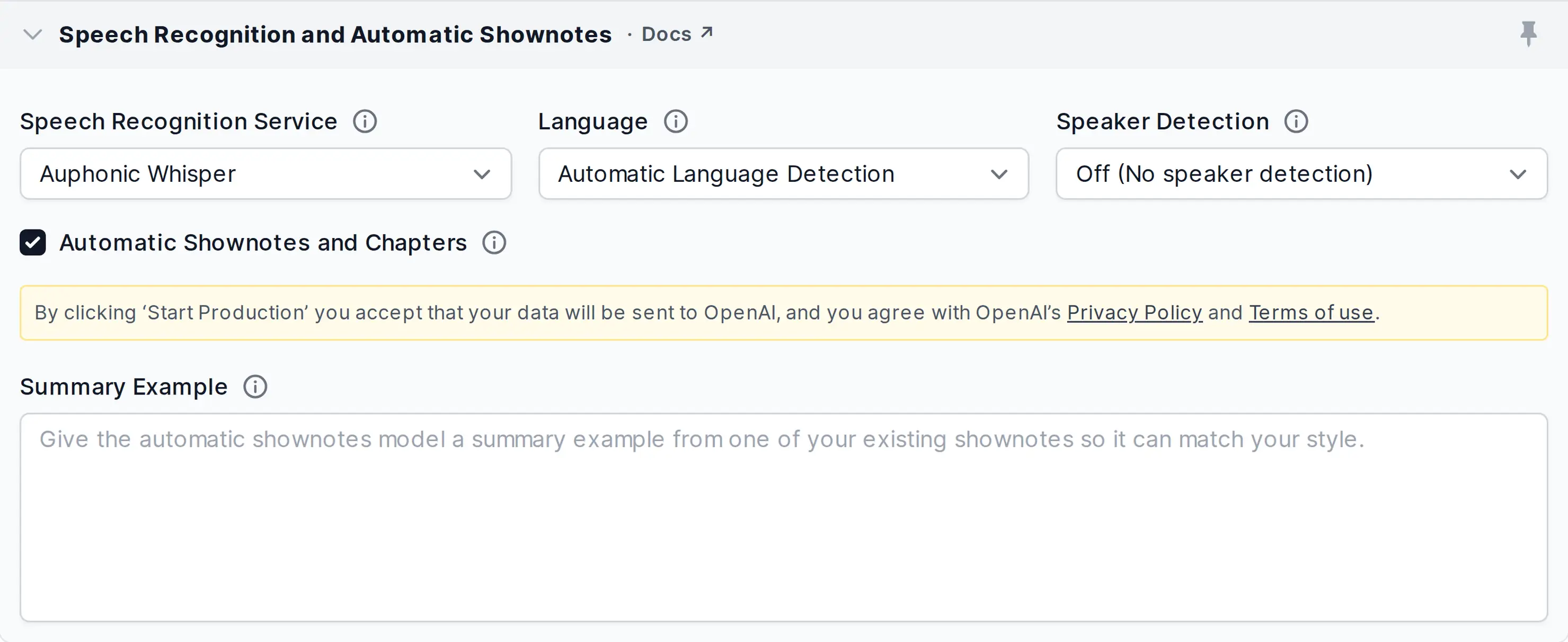
You can automatically generate shownotes and chapters by checking the Automatic Shownotes and Chapters Checkbox in the Auphonic singletrack or multitrack Production Form with any of our ASR Services enabled.
Once your production is done, the generated data will show up in your transcript result files and in the
Auphonic Transcript Editor above the speech recognition transcript section, like you can see in our Example Production.
By clicking on a chapter title in the Chapters section of the transcript editor, you can jump directly to that chapter in your transcript to review and edit that section.
Unless you have manually entered content before, the generated data will also be stored in your audio files’ metadata as follows:
Generated Long Summary stored in metadata field Summary.
Generated Subtitle stored in metadata field Subtitle.
Generated Keywords stored in metadata field Tags.
Generated Timestamps for thematic sections stored as Start Time of Chapters Marks.
Generated Headlines for thematic sections stored as Chapter Title of Chapters Marks.
Please note that not all of our supported Output File Formats are designed to use metadata. For details about metadata see our previous blog posts: ID3 Tags Metadata (used in MP3 output files), Vorbis Comment Metadata (used in FLAC, Opus and Ogg Vorbis output files) and MPEG-4 iTunes-style Metadata (used in AAC, M4A/M4B/MP4 and ALAC output files).
- Customization
You can use the field Summary Example to personalize the generated summary. Here, you can paste a summary from one of your existing shownotes, which will be passed to the model as an example so it can match your writing style. Your Summary Example may also include formatting such as Markdown or HTML syntax so the model can match your formatting.
Edit Autogenerated Data
If you are unhappy with any detail in the generated keywords, summaries or chapters used as metadata, you can return to your production’s status page and click Edit Production under the feedback section. The previously generated metadata will now show up in the production form (as Extended Metadata and Chapter Marks) for you to edit.
When you are finished editing, simply rerun the production to update your changes to your audio file’s metadata.
Re-running the production will NOT cost you any additional credits on your Auphonic account if you only change the metadata and settings, but do NOT change the inputfile!
Manually edited metadata would not be overwritten, however, we do recommend turning off Speech Recognition and Shownote Generation for the second run to save time and avoid additional costs for external ASR services.
Of course, you could also use any third-party software of your choice to edit the metadata after downloading.
Auphonic Whisper ASR
Using OpenAI’s open-source model Whisper, we offer a self-hosted automatic speech recognition (ASR) service.
For an overview and comparison to our integrated external ASR services, please see our Services Comparison Table.
Most important facts about Auphonic Whisper ASR:
- Price and Supported languages
Whisper supports transcriptions in about 100 languages, which you can integrate into your Auphonic audio post-production workflow without creating an external account and at no additional cost.
Except for strong accents Whisper also provides a reliable language autodetection feature.- Timestamps, Confidence Values and Punctuation
Whisper returns timestamps and confidence values, that allow you to locate specific phrases in your recording, and combined with our Transcript Editor, you can easily find sections that should be checked manually.
- ASR Speed and Quality
By using Auphonic Whisper ASR, your data does not have to leave our Auphonic servers for speech recognition processing, which speeds up ASR processing. The quality of Whisper transcripts is absolutely comparable to the “best” services in our comparison table.
Besides the fact, that Whisper is integrated in the Auphonic web service per default and you need no external account, causing extra costs, the outstanding feature with Whisper is the automatic language detection.
Integrated Speech Recognition Services
Besides our self-hosted Auphonic Whisper ASR (automatic speech recognition) service, we also support the following
integrated external ASR services: Wit.ai, Google Cloud Speech API, Amazon Transcribe and Speechmatics.
For an overview and comparison, please see our Services Comparison Table.
Wit.ai
Wit.ai, owned by Facebook, provides an online natural language processing platform, which also includes speech recognition.
Wit is free, including for commercial use. See FAQ and Terms .
It supports many languages, but you have to create a separate Wit.ai service for every language you use!
Google Cloud Speech API
Google Cloud Speech API is the speech to text engine developed by Google and supports over 100 languages.
60 minutes of audio per month and model are free, for more see Pricing (about $1.5/h for default model).
For English (en-US), we use the more expensive Enhanced Model (about $2.2/h for enhanced model), which gives much better results.
In your Google Cloud account you can optionally give Google permission to apply Data Logging to reduce your costs to ~$1/h default and ~$1.5/h enhanced model.
It is possible to add keywords to improve speech recognition accuracy for specific words and phrases or to add additional words to the vocabulary. For details see Word and Phrase Hints.
A great feature of the Google Speech API is the possibility to add keywords (also available in Amazon Transcribe and Speechmatics), which can improve the recognition quality a lot!
We automatically send words and phrases from your metadata (title, artist, chapters, track names, tags, etc.) to Google and you can add additional keywords manually (see screenshot above).
This provides a context for the recognizer and allows the recognition of nonfamous names (e.g the podcast host) or out-of-vocabulary words.
Amazon Transcribe
Amazon Transcribe offers accurate transcriptions in many languages at low costs, including keywords, word confidence, timestamps, and punctuation.
- Pricing
The free tier offers 60 minutes of free usage a month for 12 months. After that, it is billed monthly at a rate of $0.0004 per second ($1.44/h). More information is available at Amazon Transcribe Pricing.
- Custom Vocabulary (Keywords) Support
Custom Vocabulary (called Keywords in Auphonic) gives you the ability to expand and customize the speech recognition vocabulary, specific to your case (i.e. product names, domain-specific terminology, or names of individuals).
The same feature is also available in the Google Cloud Speech API and in Speechmatics.- Timestamps, Word Confidence, and Punctuation
Amazon Transcribe returns a timestamp and confidence value for each word so that you can easily locate the audio in the original recording by searching for the text.
It also adds some punctuation, which is combined with our own punctuation and formatting automatically.
The high quality, especially in combination with keywords, and low costs of Amazon Transcribe make the service very attractive.
However, the processing time of Amazon Transcribe is much slower compared to all our other integrated services!
Speechmatics
Speechmatics offers accurate transcriptions in many languages including word confidence values, timestamps, punctuation and custom dictionary (called Keywords in Auphonic).
- Languages and Keywords
Speechmatics supports all major European, American and some Asiatic languages and takes a global language approach. That means various accents and dialects, like Indian English or Austrian German, are very well recognized even though you cannot explicitly select a specific language region.
Also the Custom Dictionary feature (called Keywords in Auphonic), which does further improve the results, is now available in the Speechmatics API.- Model Accuracy
There are two levels of accuracy for Speechmatics that you can choose when you create the Service within Auphonic for the first time. The Standard Model works much faster than the Enhanced Model, is lower in costs but still in equal accuracy range as the other services.
For the Enhanced Model you have to be more patient, as processing takes nearly as long as with Amazon Transcribe, but the quality of the result is correspondingly high. In terms of punctuation and small details in pronunciation the Enhanced Model of Speechmatics is incomparably good.Note
If you want to use both Standard and Enhanced Model of Speechmatics once in a while, you need to create two separate services (one service for each model) in your Auphonic account!
- Timestamps, Word Confidence, and Punctuation
Like Amazon Transcribe, Speechmatics creates timestamps, word confidence values, and punctuation for every single word.
- Pricing
Speechmatics offers 4 hours of free speech recognition per month (2h standard model plus 2h enhanced model). Once you exceed these 4 hours, however, Speechmatics is at similar cost to the Google Cloud Speech API (or lower).
Pricing starts at $1.25 per hour of audio for Standard Model up to $1.90/h for Enhanced Model. They offer significant discounts for users requiring higher volumes. If you process a lot of content, you should contact them directly at hello@speechmatics.com and say that you wish to use it with Auphonic.
More information is available at Speechmatics Pricing.
Services Comparison Table
Auphonic Whisper |
Wit.ai |
Google Speech API |
Amazon Transcribe |
Speechmatics Standard |
Speechmatics Enhanced |
|
|---|---|---|---|---|---|---|
Price |
free, |
free, |
1+1h free per month |
1h free per month |
2h free per month, |
2h free per month, |
ASR Quality English |
best |
basic |
good |
very good |
very good |
best |
ASR Quality German |
best |
basic |
basic |
very good |
very good |
best |
Keyword Support |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Timestamps and Confidence Value |
Yes |
No |
No |
Yes |
Yes |
Yes |
Speed |
fast |
slow |
fast |
much slower |
medium |
fast |
Supported Languages |
(Last Update: March 2023)
More Details about the comparison:
- ASR Quality:
We tried to compare the relative speech recognition quality of all services in English and German (best means just the best one of our integrated services).
Please let us know if you get different results or if you compare services in other languages!- Keyword Support:
Support for keywords to expand the speech recognition vocabulary, to recognize out-of-vocabulary words.
This feature is called Word and Phrase Hints in the Google Cloud Speech API, Custom Vocabulary in Amazon Transcribe and Custom Dictionary in Speechmatics.- Timestamps and Confidence Value:
A timestamp and confidence value is returned for each word or phrase.
This is relevant for our Transcript Editor, to play each word or phrase separately and to instantly see which sections should be checked manually (low confidence).- Speed:
The relative processing speed of all services. All services are faster than real-time, but Amazon Transcribe and Speechmatics enhanced model are significantly slower compared to all other services.
- Supported Languages:
Links to pages with recent supported languages and variants.
We will add additional services if and when we find services that offer improved cost benefits or better final results and support at least two languages (that’s an important step for a speech recognition company).
Auphonic Output Formats
Auphonic produces three output formats from speech recognition results:
An HTML transcript file (readable by humans), a JSON or XML file with all data (readable by machines) and a WebVTT subtitles/captions file as an exchange format between systems.
HTML Transcript File
Examples: EN Singletrack, EN Multitrack, DE Singletrack
The HTML output file contains the transcribed text with timestamps for each new paragraph, mouse hover shows the time for each text segment and speaker names are displayed in case of multitrack. Sections are automatically generated from chapter marks and the HTML file includes the audio metadata as well.
The transcription text can be copied into Wordpress or other content management systems, in order to search within the transcript and to find the corresponding timestamps (if you don’t have an audio player which supports search in WebVTT/transcripts).
Our HTML output file also includes the Auphonic Transcript Editor for easy-to-use transcription editing.
WebVTT File
Examples: EN Singletrack, EN Multitrack, DE Singletrack
WebVTT is the open specification for subtitles, captions, chapters, etc. The WebVTT file can be added as a track element within the HTML5 audio/video element. For an introduction see Getting started with the HTML5 track element.
It is supported by all major browsers and also many other systems use it already (screenreaders, (web) audio players with WebVTT display+search like the player from Podlove, software libs, etc.).
It is possible to add other time-based metadata as well: Not only the transcription text, also speaker names, styling or any other custom data like GPS coordinates are possible.
Search engines could parse WebVTT files in audio/video tags, as the format is well defined,
then we would have searchable audio/video.
It is also possible to link to an external WebVTT file in an RSS feed, then podcast players and other feed-based systems could parse the transcript as well (for details see this discussion).
WebVTT is therefore a great exchange format between different systems: audio players, speech recognition systems, human transcriptions, feeds, search engines, CMS, etc.
JSON/XML Output File
Examples: EN Singletrack, EN Multitrack, DE Singletrack
This file contains all the speech recognition details in JSON or XML format. This includes the text, punctuation and paragraphs with timestamps and confidence values.
Word timestamps and confidence values are available if you use Auphonic Whisper ASR, Speechmatics or Amazon Transcribe.
Tips to Improve Speech Recognition Accuracy
- Audio quality is important
Reverberant audio is quite a problem, put the microphone as close to the speaker as possible.
Try to avoid background sounds and noises during recording.
Don’t use background music either (unless you use our multitrack version).
Only use fast as well as stable skype/hangout connections.
- Speak clearly
Pronunciation and grammar are important.
Dialects are more difficult to understand, use the correct language variant if available (e.g. English-UK vs. English-US).
Don’t interrupt other speakers. This has a huge impact on the accuracy!
Don’t mix languages.
- Use a lot of metadata and keywords
This is a big help for the Google Speech API, Amazon Transcribe and Speechmatics.
When using metadata and keywords, it contributes a lot to make the recognition of special names, terms and out-of-vocabulary words easier.
As always, accurate metadata is important!
- Use our multitrack version
If you record a separate track for each speaker, use our multitrack speech recognition.
This will lead to better results and more accurate information on the timing of each speaker.
Background music/sounds should be put into a separate track, so as to not interfere with the speech recognition.
Auphonic Transcript Editor
Our Transcript Editor, which is embedded directly in the HTML Transcript File, has been designed to make reviewing and editing transcripts as easy as possible. Try it yourself with our Transcript Editor Examples.

Note
If you are using Automatic Speech Recognition in combination with our Cut Silence Algorithms, the timestamps in the Transcript Editor are matching with the cut output audio file.
Main Features of the Transcript Editor
Subtitle/Line Mode
Your transcript is being visualized in Paragraph Mode by default. Use the Subtitle/Line Mode toggle located in the ⋮ More Options Menu (bottom right) to enable Subtitle/Line Mode which allows for more precise editing of every single subtitle.
Note
One line in the Subtitle/Line Mode represents one subtitle (*.vtt, *.srt).
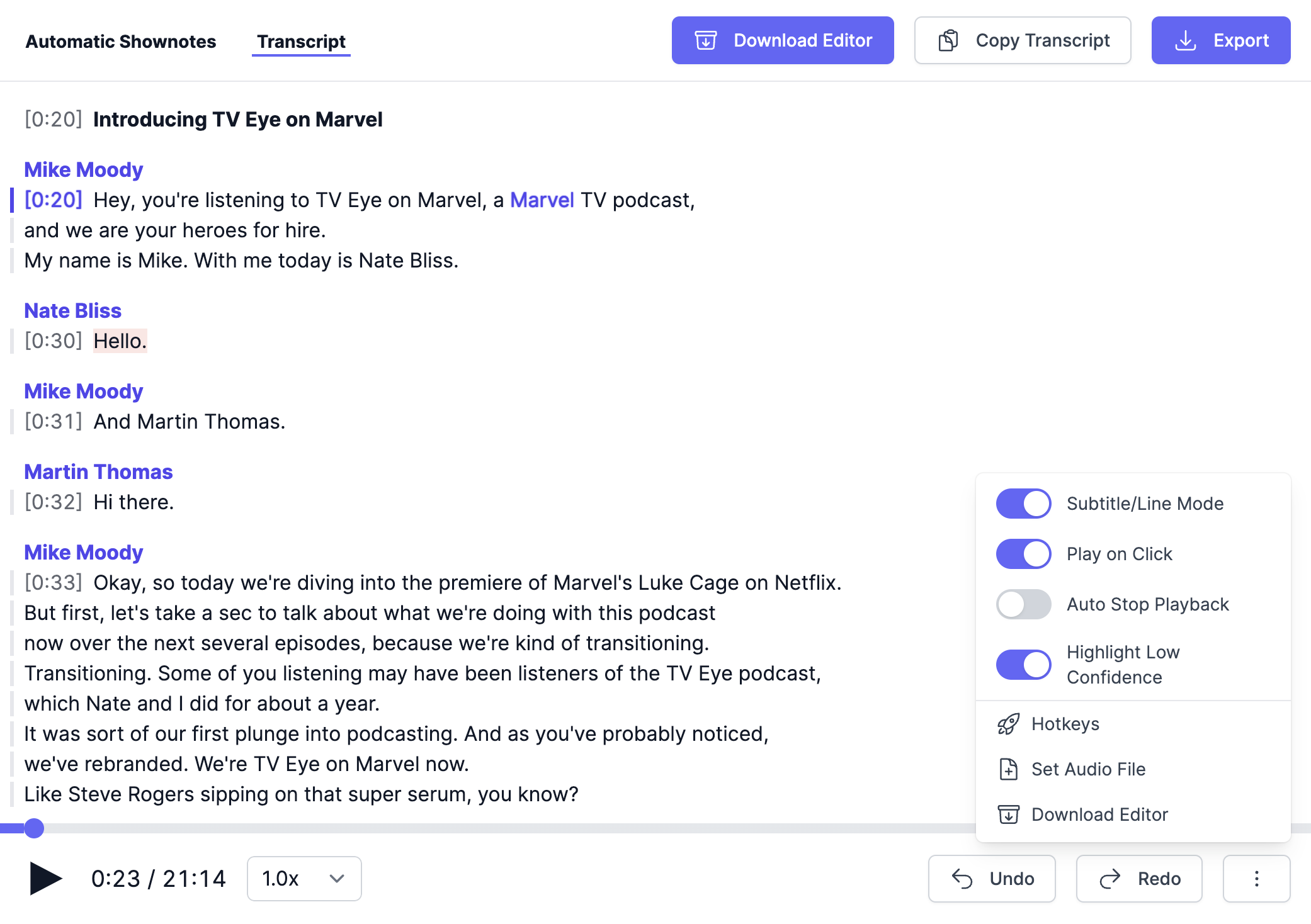
Screenshot of the Subtitle/Line Mode. You can see 1 Chapter, 5 Paragraphs and 14 Lines in this Screenshot.
Editing and Local History
Depending on the speech recognition engine, editing can be done on word or phrase level.
Press the Enter key to split lines or paragraphs.
Press the Backspace key at the beginning of a line to combine lines or paragraphs.
Use the undo/redo buttons located in the Playback Bar to undo/redo any changes made. This functionality is covering the entire transcript, including changes made in Automatic Shownotes and Chapters.
Note
Keep in mind: the local history captures all changes until the page is reloaded. Reloading the page will clear the history.
Hotkeys
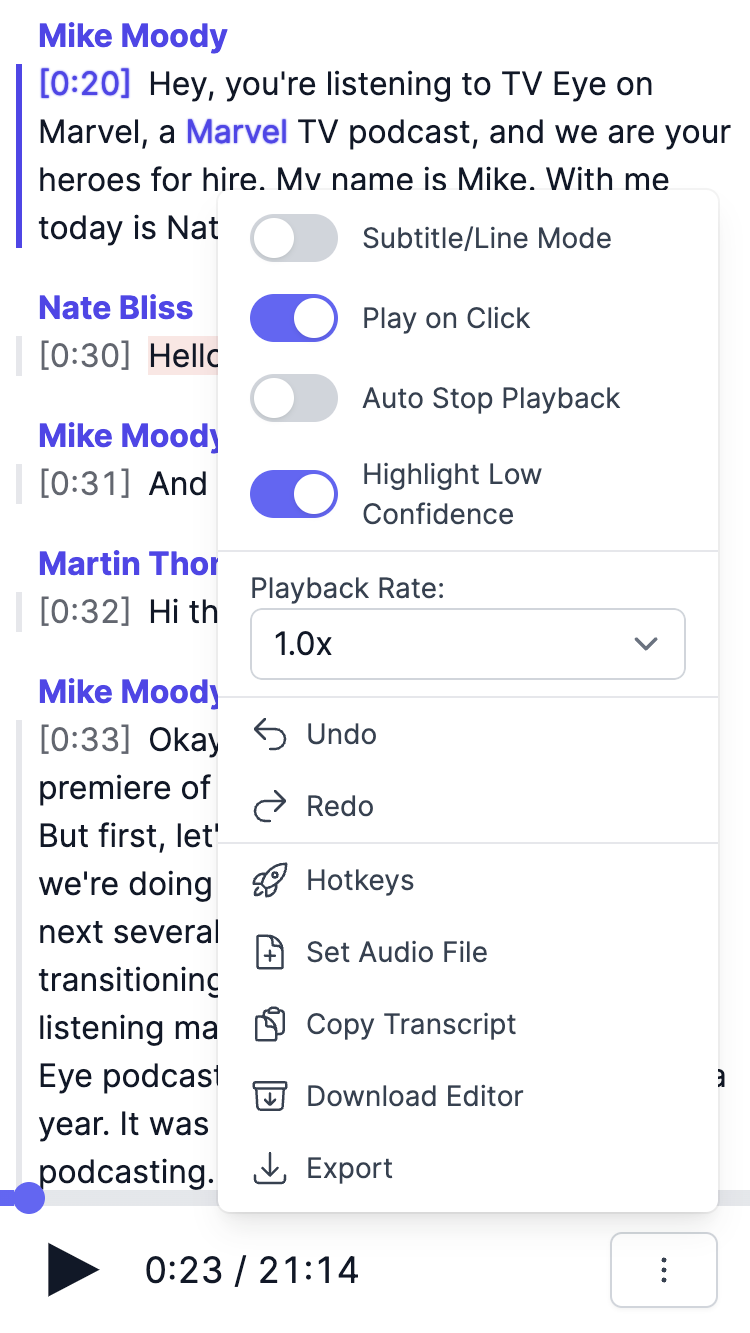
Use the Hotkeys action located in the ⋮ More Options Menu (bottom right) to view and edit available Hotkeys.
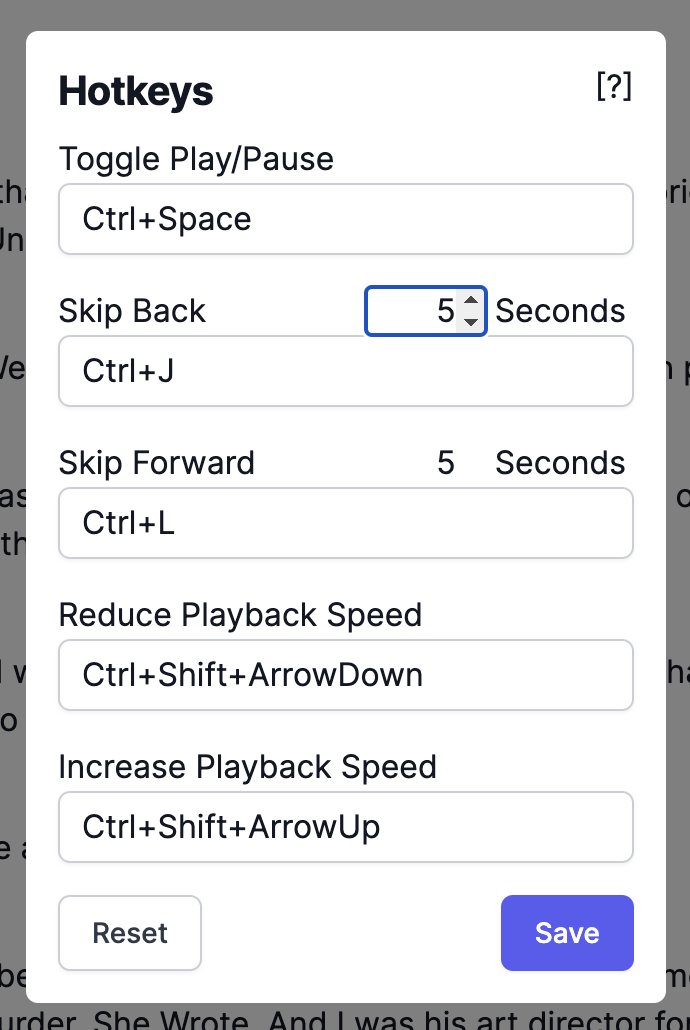
In addition to Code values for keyboard events, we offer simplified key combinations for alphanumeric keycodes, as demonstrated in the screenshot. This allows you to define hotkeys using a more intuitive syntax, such as “Ctrl+J” rather than “Ctrl+KeyJ”.
To update a hotkey, simply enter the desired combination as text and press Save.
You are also able to adjust Skip Back/Skip Forward seconds in this dialog.
Use the Reset button to reset the Hotkeys to default.
Automatic Shownotes and Chapters
Enable Automatic Shownotes and Chapters in the production form, to include AI-generated summaries, tags and chapters in the Transcript Editor. This allows you to edit chapter text, summaries, and tags within the Automatic Shownotes section of the editor.
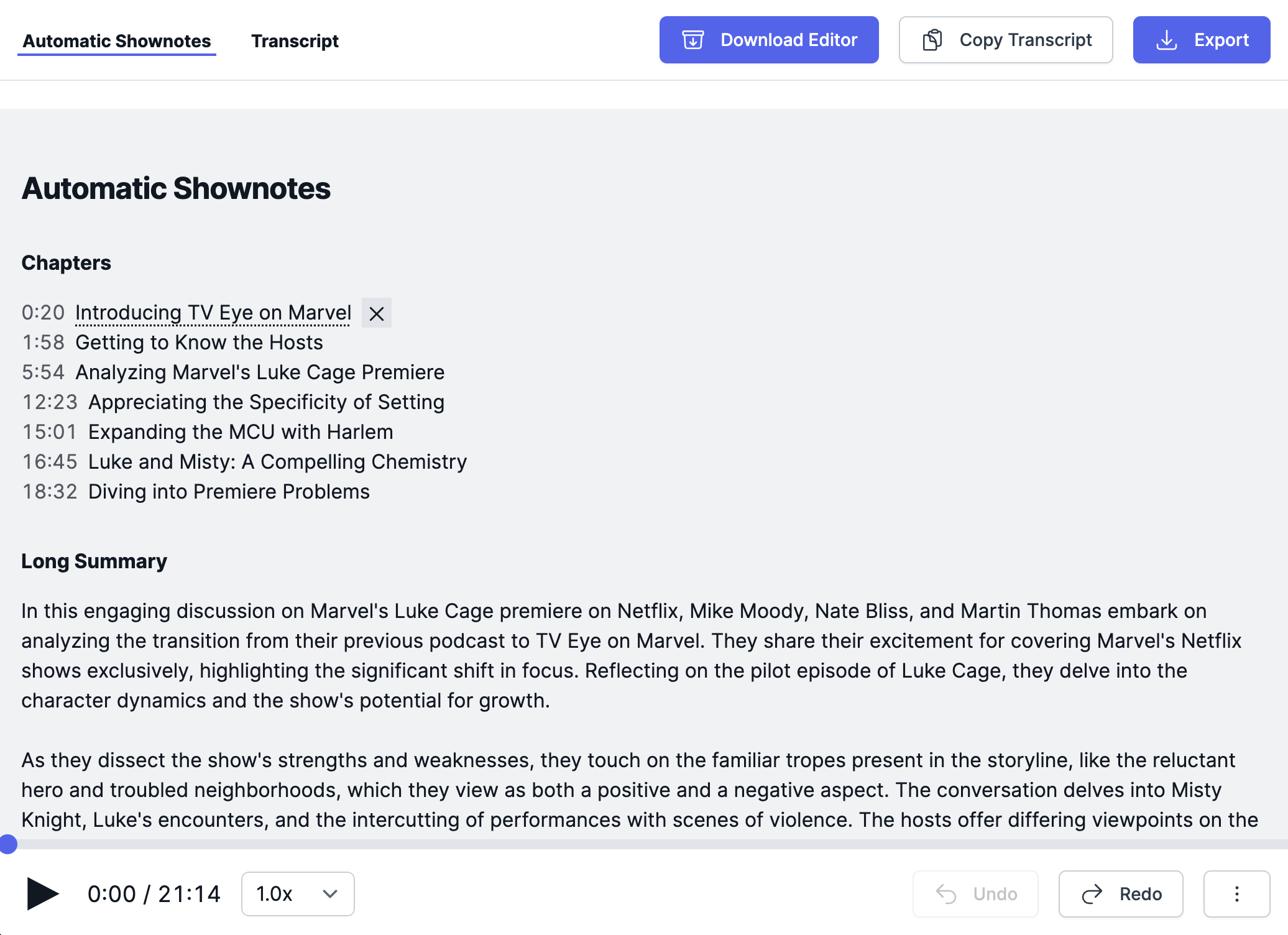
Please note that editing chapter times is limited to the Transcript section of the editor to ensure precise placement of chapters.

Highlight Low Confidence
Word or phrase confidence values are shown visually in the Transcript Editor, highlighted in shades of red.
The shade of red is dependent on the actual word confidence value: The darker the red, the lower the confidence value. This means you can instantly see which sections you should check/re-work manually to increase the accuracy.

Once you have edited the highlighted text, it will be set to white again, so it’s easy to see which sections still require editing.
Use the Highlight Low Confidence switch in the ⋮ More Options Menu (bottom right) to toggle this feature.
Note
Confidence values are only available in Auphonic Whisper ASR, Amazon Transcribe and Speechmatics. They are not supported if you use any of our other integrated speech recognition services!
Edit Speakers
In Multitrack Productions, speakers are automatically assigned via the Track Identifier. You can edit or add new speakers directly within the Transcript Editor. Simply click on a speaker to toggle this menu.
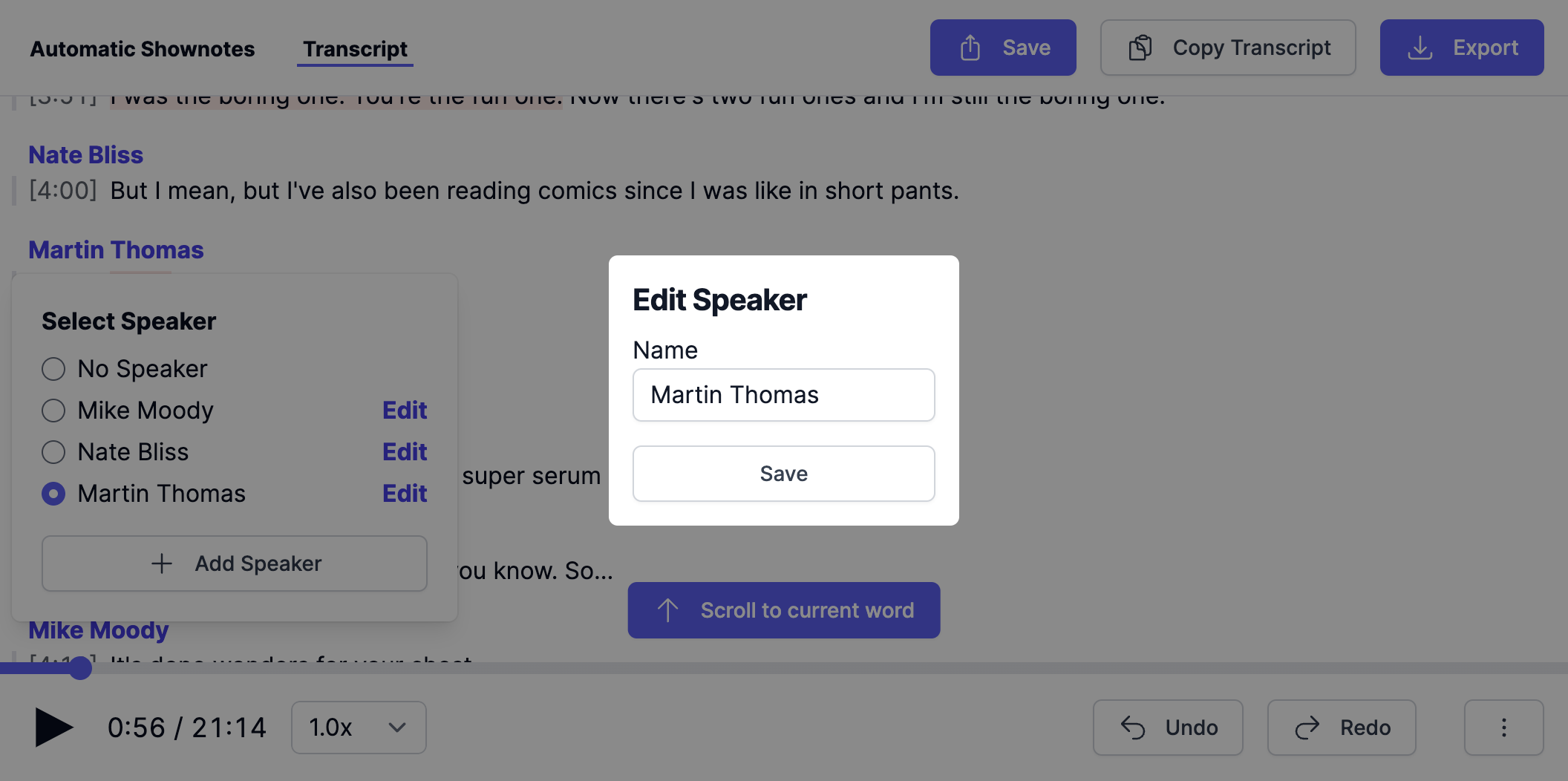
After clicking Save, any Track Identifiers within the production are also updated accordingly.
Playback
The Playback Bar provides Play/Pause functionality. Use the Playback Rate Dropdown to adjust playback speed. Additionally, you can navigate through the playback and transcript using the Playback Slider.

If you use an External Service in your production to export the resulting audio file, we will automatically use the exported file in the Transcript Editor.
Otherwise we will use the output file generated by Auphonic. Please note that this file is password protected for the current Auphonic user and will be deleted in 21 days.
Note
If the audio file is not available, or cannot be played because of the password protection, you will see the Set Audio File button.

Play on Click
This functionality enables you to start the audio playback on the word or phrase you click on.
It allows you to verify the accuracy of specific words while editing, eliminating the need to search for that section within your audio file.
Use the Play on Click switch in the ⋮ More Options Menu (bottom right) to toggle this feature.
Export
Use the Export action (top right) to see all available export options:
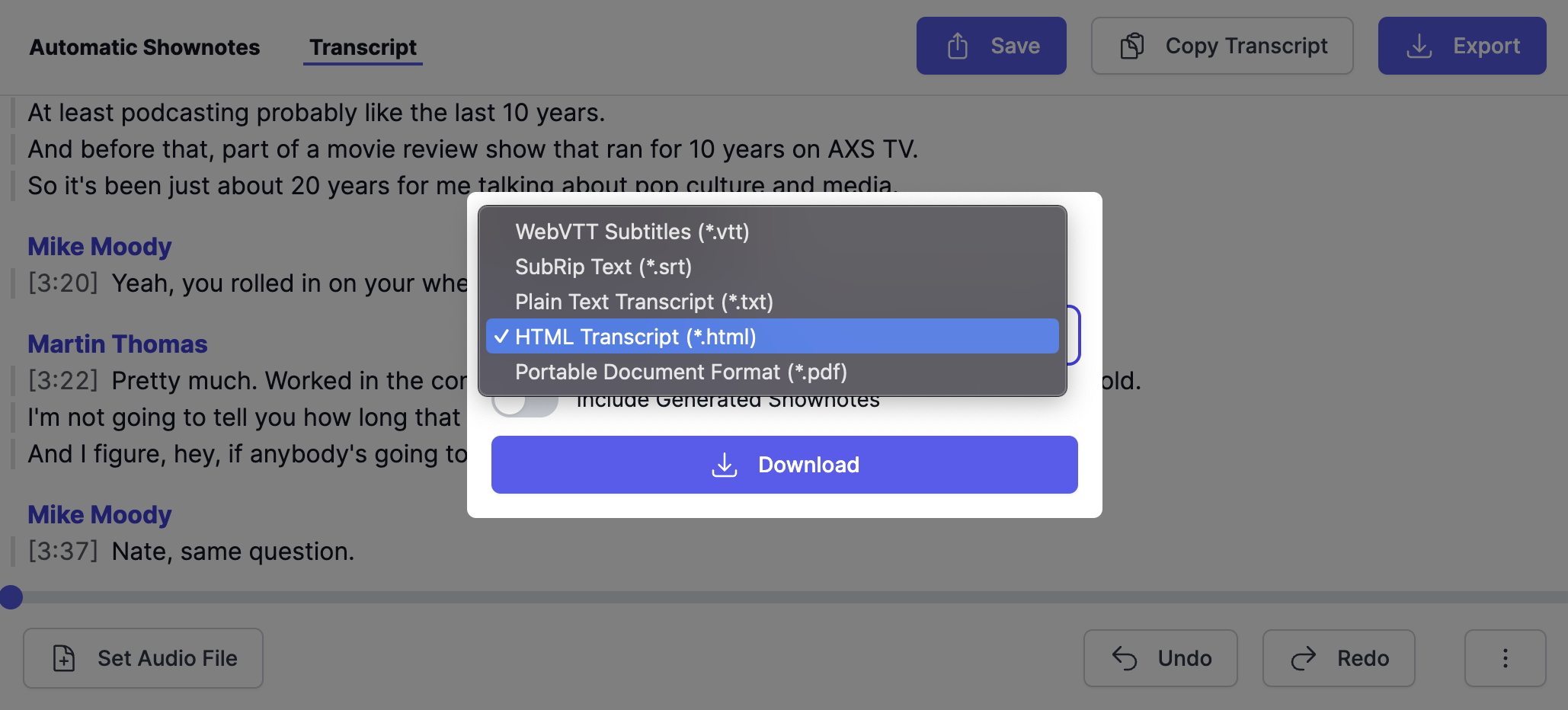
You can export the transcript to the following formats:
WebVTT Subtitles (.vtt): This is a format used for displaying timed text tracks, such as subtitles, alongside multimedia content. It’s widely supported across many platforms and tools.
SubRip Text (.srt): This format is a simple subtitle file format for displaying subtitles alongside multimedia content. It’s also widely supported across many platforms and tools.
Plain Text Transcript (.txt): This format exports the transcript in a simple text format without any formatting or styling.
HTML Transcript (.html): Export the transcript in unstyled HTML optimized for printing and readability. This format ensures that the transcript is presented in a clear and legible manner when printed or viewed in a web browser, without any additional formatting or styling.
Portable Document Format (.pdf): Utilize the HTML transcript and open the printing dialog to generate a PDF. This method ensures that the transcript is printed or saved as a PDF with optimal formatting and layout for easy readability.
Save
Use the Save button (top right) to save any changes back to the production, including any modifications made within the Automatic Shownotes and Chapters.
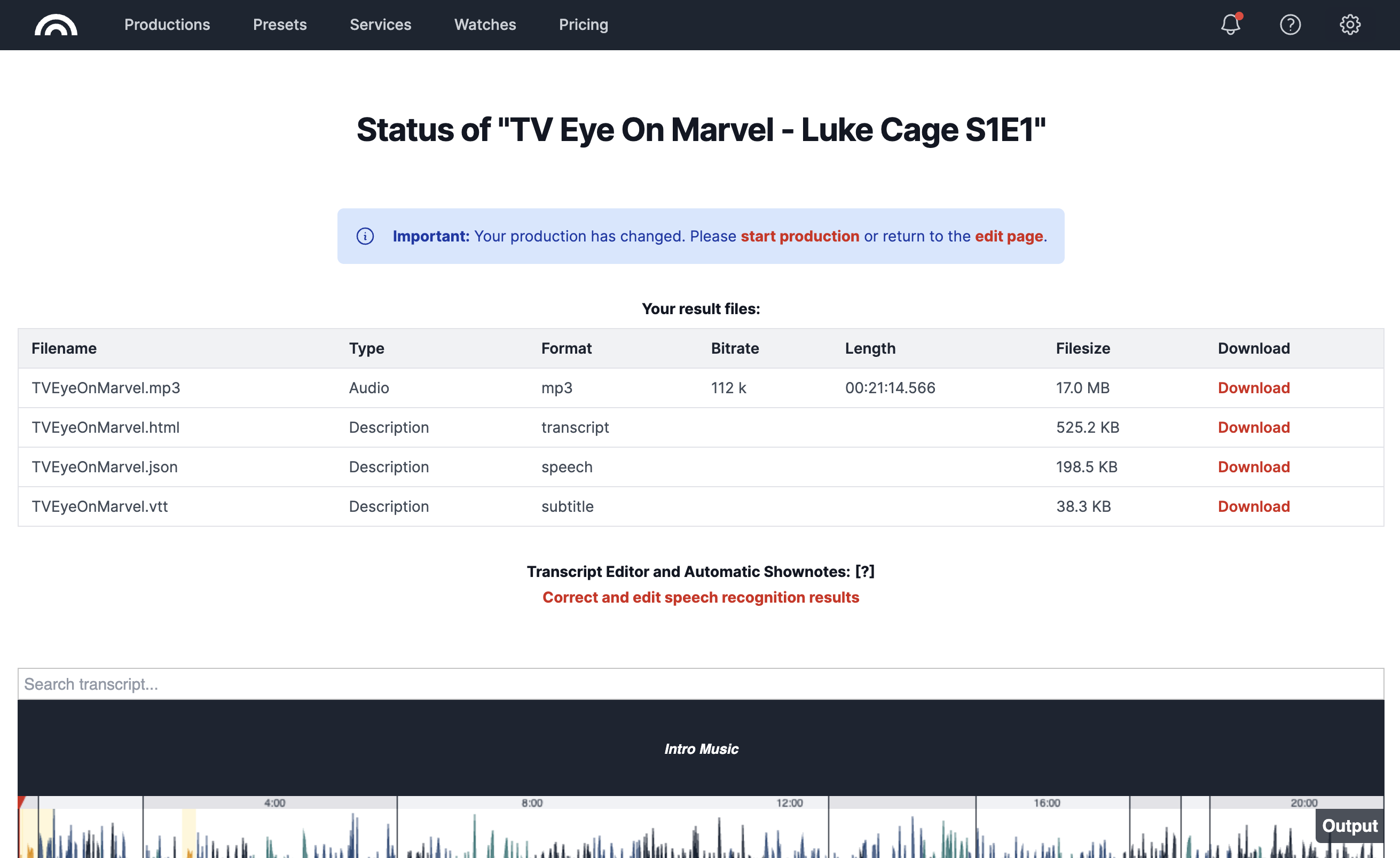
Screenshot of the production status page after Save.
After saving, your production status will be updated to Production Changed. Click start production to reprocess the production with the updated transcript. Your edited transcript (including modifications in chapters, tags, and summaries) will be utilized to generate the result files.
Note
Save and Select Transcript Version are only available if you open the Transcript Editor directly on the production status page via Correct and edit speech recognition results.
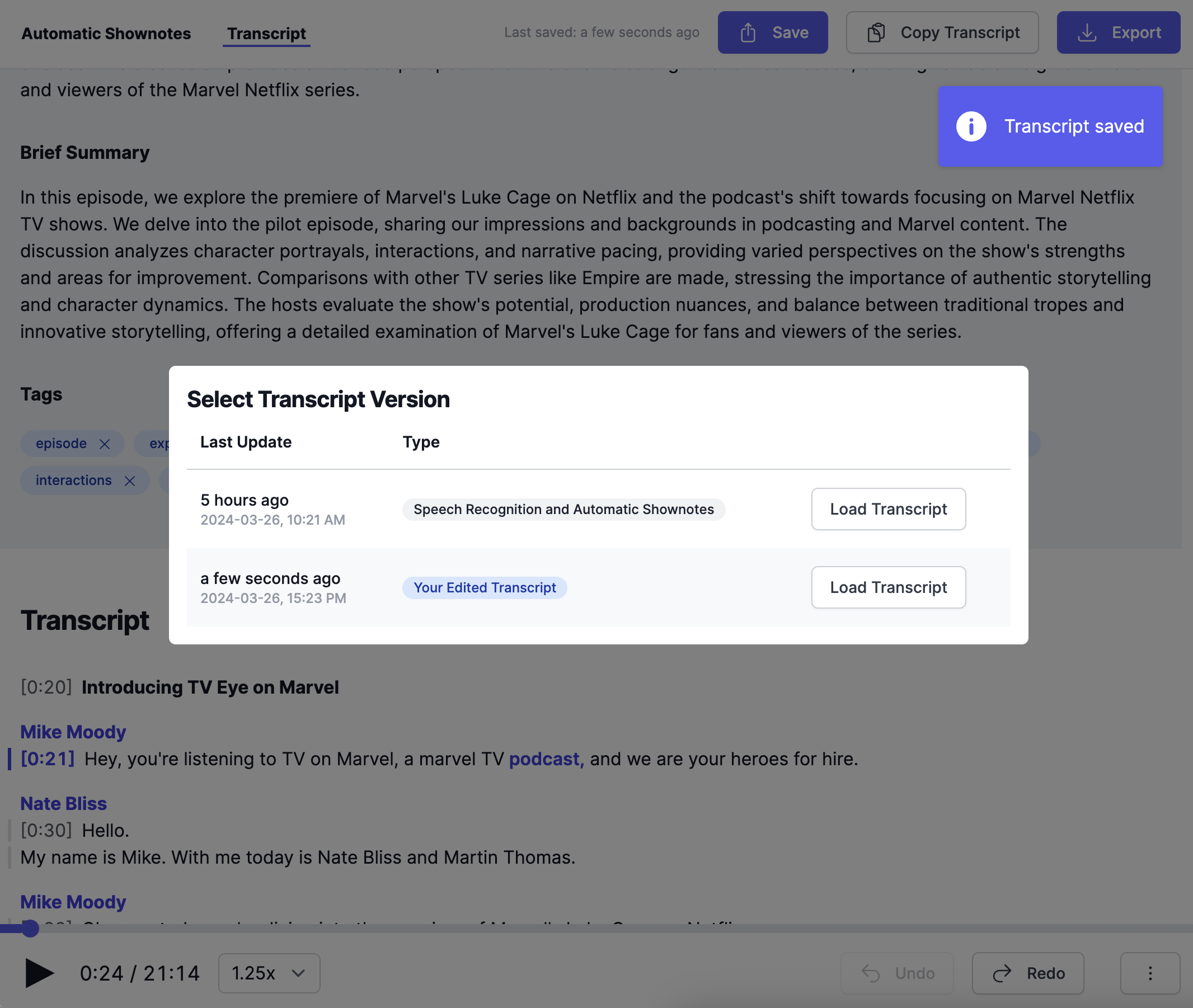
Select Transcript Version
Once your transcript has been saved back to the production, you can switch between two versions: Your Edited Transcript and the latest Speech Recognition and Automatic Shownotes result. Use the Select Transcript Version action in the ⋮ More Options Menu (bottom right) to open this Dialog.
Note
Keep in mind: Chapters are not part of this versioning. Chapters are saved to production when you save the transcript and loaded from production when opening the transcript.
Design for Mobile Devices
The Transcript Editor has been optimized for desktop and mobile devices. On mobile devices, you can find all available actions when you click on the ⋮ More Options Menu (bottom right).
Speech Recognition Examples
Please see examples in English and German at:
https://auphonic.com/features/speechrec
All features demonstrated in these examples also work in over 100 languages, although the recognition quality might vary.
Transcript Editor Examples
Here are two examples of the Transcript Editor, taken from our Speech Recognition Examples:
- 1. Singletrack Transcript Editor Example
Singletrack speech recognition example from the first 10 minutes of Common Sense 309 by Dan Carlin.
Auphonic Whisper ASR was used as speech recognition engine without any further manual editing.- 2. Multitrack Transcript Editor Example
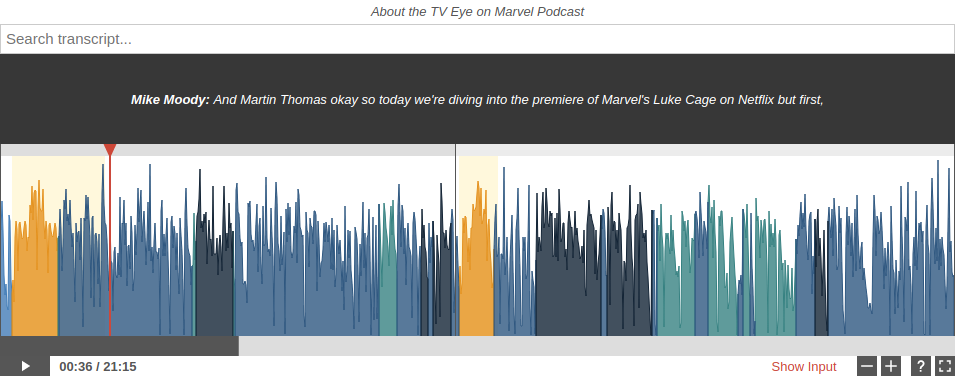
A multitrack speech recognition transcript example from the first 20 minutes of TV Eye on Marvel - Luke Cage S1E1.
Auphonic Whisper ASR was used as speech recognition engine without any further manual editing.
As this is a multitrack production, the transcript includes exact speaker names as well (try to edit them!).