Today we are thrilled to introduce revised parameters for the
Adaptive Leveler
to move our
advanced algorithms out of beta.
The leveler can now run in three modes, which allow detailed
Leveler Strength control and also the use of Broadcast Parameters
(Max. Loudness Range, Max. Short-term Loudness, Max. Momentary Loudness)
to limit the amount of leveling.
 Photo by Gemma Evans.
Photo by Gemma Evans.
When we first
introduced our advanced parameters,
we used the
Maximum Loudness Range (MaxLRA) value to control the strength of our leveler.
This gave good results, but it turned out that
only pure speech programs give reliable and comparable LRA values
and it was sometimes difficult to set a loudness range target for diverse audio content.
To resolve this issue, we reworked the parameter and called it
Dynamic Range.
After discussions with our users, however, we received the feedback that the name
Dynamic Range was too confusing, so we decided to call
it Leveler Strength.
In our discussions with users, we were also told they like to be able
to set a loudness range target to limit the amount of leveling,
because MaxLRA is often used by broadcasters and in regulations.
As a solution, we added a Broadcast Mode,
which makes it now possible to use the MaxLRA, MaxS, and MaxM values to control
the strength of our leveler as well.
In this blog post, we will first discuss the new parameters - Leveler Strength, Music Gain, MusicSpeech Classifier Settings, MaxLRA, MaxS, and MaxM - of our Singletrack Advanced Leveler, then we will show how these settings can be used in the Multitrack Advanced Leveler.
Singletrack Advanced Leveler
The Adaptive Leveler normalizes all speakers to a similar loudness so that a consumer in a car or subway doesn't feel the need to reach for the volume control. However, in other environments (living room, cinema, etc.) or in dynamic recordings, you might want more level differences (Dynamic Range, Loudness Range / LRA) between speakers and within music segments.
Our new parameters let users control the Leveler Strength
to adjust mid-term level differences,
similar to a sound engineer using the faders of an audio mixer,
and Compressor Settings
for
short-term dynamics control.
The Advanced Leveler can be used in three different Modes:
Default Mode, Separate MusicSpeech Parameters, and Broadcast Mode.
For more details, please see our Leveler Parameters Help.
Default Mode

- Leveler Strength:
-
The Leveler Strength controls how much leveling is applied:
100% means full leveling, 0% means no leveling at all.
Changing the Leveler Strength increases/decreases the Dynamic Range of the output file.
Example Use Case:
Lower Leveler Strength values should be used if you want to keep more loudness differences in dynamic narration or dynamic music recordings (live concert/classical). - Compressor Settings:
-
Here you can select a preset value for micro-dynamics compression.
A compressor reduces the volume of short and loud spikes like the pronunciation of "p" and "t" or laughter (short-term dynamics) and also shapes the sound of your voice (making the sound more or less "processed" or "punchy").
Separate MusicSpeech Parameters
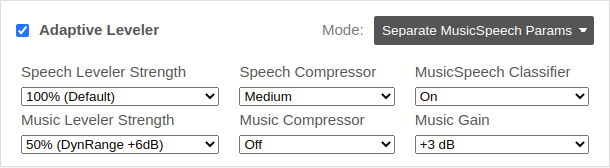
In the Separate MusicSpeech Parameters mode, independent settings for music and speech segments
(Music Leveler Strength, Music Compressor)
can be selected.
These settings allow you to use, for example, more leveling in speech segmets while keeping music and FX elements less processed.
You can also disable our music/speech classifier or add a gain to music segments:
- MusicSpeech Classifier:
- Use our speech/music classifier to level music and speech segments separately, or override the classifier decision and treat the whole audio file as speech or music.
- Music Gain:
- Add a gain to music segments, to make music louder or softer compared to the speech parts. Use the default setting (0 dB) to give music and speech parts a similar average loudness.
Broadcast Mode
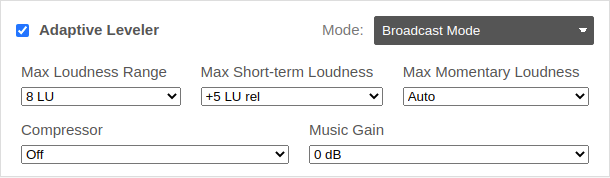
The Broadcast Mode uses different parameters, which are often used by broadcasters and in regulations, to control the Leveler Strength:
- Maximum Loudness Range (LRA):
-
The loudness range (LRA) indicates the variation of loudness throughout
a program and is measured in LU (loudness units) - for more details see
Loudness Measurement and Normalization or
EBU Tech 3342.
The volume changes of our Leveler will be restricted so that the LRA of the output file is below the selected value (if possible).
High LRA values will result in very dynamic output files, whereas low LRA values will result in compressed output audio. If the LRA value of your input file is already below the maximum loudness range value, no leveling at all will be applied.
Loudness Range values are most reliable for pure speech programs: a typical LRA value for news programs is 3 LU; for talks and discussions, an LRA value of 5 LU is common. LRA values for features, radio dramas, movies, or music strongly depend on the individual character and might be in the range of 5 to 25 LU - for more information, please see Where LRA falls short.
Netflix, for instance, recommends an LRA of 4 to 18 LU for the overall program and 7 LU or less for dialog. - Maximum Short-term Loudness (MaxS):
-
Set a Maximum Short-term Loudness target
(3s measurement window, see EBU Tech 3341, Section 2.2)
relative to your Global Loudness Normalization Target.
Our Adaptive Leveler will ensure that the MaxS loudness value of the output file, which are loudness values measured with an integration time of 3s, will be below this target (if possible).
For example, if the MaxS value is set to +5 LU relative and the Loudness Target to -23 LUFS, then the absolute MaxS value of your output file will be restricted to -18 LUFS.
The Max Short-term Loudness is used in certain regulations for short-form content and advertisements.
See for example EBU R128 S1: Loudness Parameters for Short-form Content (advertisements, promos, etc.), which recommends a Max Short-term Loudness of +5 LU relative. - Maximum Momentary Loudness (MaxM):
-
Similar to the MaxS target, it's also possible to use a
Maximum Momentary Loudness target
(0.4s measurement window, see EBU Tech 3341, Section 2.2)
relative to your Global Loudness Normalization Target.
Our Adaptive Leveler will ensure that the MaxM loudness value of the output file, which are loudness values measured with an integration time of 0.4s, will be below this target (if possible).
The Max Momentary Loudness is used in certain regulations by broadcasters. For example, CBC and Radio Canada require that the Momentary Loudness must not exceed +10 LU above the target loudness.
If it's not possible for the levels of the output file to be below the given MaxLRA, MaxS, or MaxM target values, you will receive a warning message via email and on the production page.
Example Use Case:
The broadcast parameters can be used to generate automatic mixdowns with different LRA values
for different target environments (very compressed environments like mobile devices or Alexa, or very dynamic ones like home cinema, etc.).
Multitrack Advanced Leveler
The new leveling parameters are also available in our
multitrack version.
Here you can set separate leveling parameters per track,
and also use broadcast parameters in the
final mixdown, to ensure that your levels are below the given
MaxLRA, MaxS, or MaxM target values.
Leveling Parameters per Track
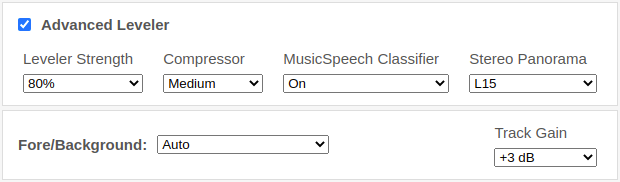
The parameters Leveler Strength, Compressor, MusicSpeech Classifier, Stereo Panorama, and Track Gain allow you to customize which parts of the track audio should be leveled, how much they should be leveled, and how much dynamic range compression should be applied.
- MusicSpeech Classifier Setting:
-
Select between the Speech Track and Music Track Adaptive Leveler.
If this is set to On, a classifier will decide if this is a music or speech track. - Stereo Panorama (Balance):
- Change the stereo panorama (balance for stereo input files) of the current track.
- Track Gain: (in the Fore/Background section)
-
Increase/decrease the loudness of this track compared to other tracks.
This can be used to add gain to a music or a specific speech track, making it louder/softer compared to other tracks.
For more details, please see Multitrack Leveler Parameters Help.
Leveling Master Parameters
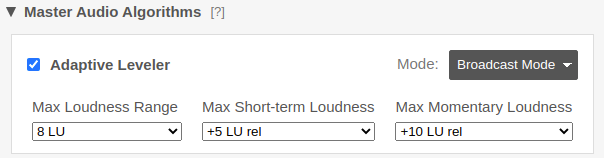
In addition to our
track parameters, you can
switch the Leveler Mode in the master algorithm settings to Broadcast Mode
to control the combined leveling strength.
Volume changes of our leveling algorithms
will be adjusted so that the final mixdown of the multitrack production
meets the given MaxLRA, MaxS, or MaxM target values - as is done in the Singletrack Broadcast Mode.
For more details, please see Master Algorithm Parameters Help.
Summary
We revised the leveling parameters to end the beta phase of our
advanced algorithms.
All advanced settings are stable and will not change significantly going forward.
- Leveler Strength: control the strength of the leveling algorithm
- Compressor: select a preset for short-term dynamics control
- Music Gain / Track Gain: make music parts louder/softer compared to speech parts
- MusicSpeech Classifier: use our classifier or set everything to speech/music
- Separate MusicSpeech Parameters Mode: separate controls for speech and music parts
- Broadcast Mode: use the parameters Maximum Loudness Range (MaxLRA), Maximum Short-term Loudness (MaxS), and Maximum Momentary Loudness (MaxM) to control the leveling strength
All new settings are also available in our API, please see Singletrack and Multitrack Advanced API Settings.
Don't hesitate to contact us if you have any questions or feedback about our algorithms!