In late August, we launched the private beta program of our advanced audio algorithm parameters. After feedback by our users and many new experiments, we are proud to release a complete rework of the Adaptive Leveler parameters:
In the
previous version,
we based our Adaptive Leveler parameters on the
Loudness Range descriptor (LRA),
which is included in the
EBU R128 specification.
Although it worked, it turned out that it is very difficult to set a loudness range target for diverse audio content, which does include speech, background sounds, music parts, etc.
The results were not predictable and it was hard to find good target values.
Therefore we developed our own algorithm to measure the
dynamic range of audio signals, which works similarly for speech, music and other audio content.
The following advanced parameters for our Adaptive Leveler allow you to customize which parts of the audio should be leveled (foreground, all, speech, music, etc.), how much they should be leveled (dynamic range), and how much micro-dynamics compression should be applied.
To try out the new algorithms, please join our private beta program and let us know your feedback!
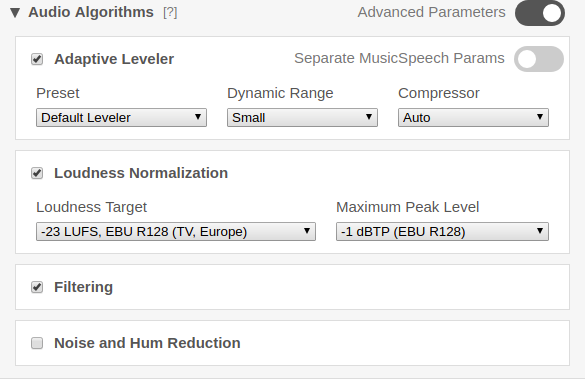
Leveler Preset
The Leveler Preset defines which parts of the audio should be adjusted by our Adaptive Leveler:
-
Default Leveler:
Our classic, default leveling algorithm as demonstrated in the Leveler Audio Examples. Use it if you are unsure. -
Foreground Only Leveler:
This preset reacts slower and levels foreground parts only. Use it if you have background speech or background music, which should not be amplified. -
Fast Leveler:
A preset which reacts much faster. It is built for recordings with fast and extreme loudness differences, for example, to amplify very quiet questions from the audience in a lecture recording, to balance fast-changing soft and loud voices within one audio track, etc. -
Amplify Everything:
Amplify as much as possible. Similar to the Fast Leveler, but also amplifies non-speech background sounds like noise.
Leveler Dynamic Range
Our default Leveler
tries to normalize all speakers to a similar loudness
so that a consumer in a car or subway doesn't feel the need to reach for the volume control.
However, in other environments (living room, cinema, etc.) or in dynamic recordings, you might want more level differences (Dynamic Range,
Loudness Range / LRA)
between speakers and within music segments.
The parameter Dynamic Range controls how much leveling is applied:
Higher values result in more dynamic output audio files (less leveling). If you want to increase the dynamic range
by 3dB (or LU), just increase the Dynamic Range parameter by 3dB.
We also like to call this Loudness Comfort Zone: above a maximum and below a minimum possible level (the comfort zone), no leveling is applied. So if your input file already has a small dynamic range (is within the comfort zone), our leveler will be just bypassed.
Example Use Cases:
Higher dynamic range values should be used if you want to keep more loudness differences in dynamic narration
or dynamic music recordings (live concert/classical).
It is also possible to utilize this parameter to generate automatic mixdowns with different loudness range (LRA) values for different target environments
(very compressed ones like mobile devices or Alexa, very dynamic ones like home cinema, etc.).
Compressor
Controls Micro-Dynamics Compression:
The compressor reduces the volume of short and loud spikes like "p", "t" or laughter
(
short-term dynamics) and also shapes the sound of your voice (it will sound more or less "processed").
The Leveler, on the other hand, adjusts
mid-term level differences, as done by a sound engineer, using the faders of an audio mixer,
so that a listener doesn't have to adjust the playback volume all the time.
For more details please see
Loudness Normalization and Compression of Podcasts and Speech Audio.
- Auto:
The compressor setting depends on the selected Leveler Preset. Medium compression is used in Foreground Only and Default Leveler presets, Hard compression in our Fast Leveler and Amplify Everything presets. - Soft:
Uses less compression. - Medium:
Our default setting. - Hard:
More compression, especially tries to compress short and extreme level overshoots. Use this preset if you want your voice to sound very processed, our if you have extreme and fast-changing level differences. - Off:
No short-term dynamics compression is used at all, only mid-term leveling. Switch off the compressor if you just want to adjust the loudness range without any additional micro-dynamics compression.
Separate Music/Speech Parameters
Use the switch Separate MusicSpeech Parameters (top right), to see separate Adaptive Leveler parameters for music and speech segments, to control all leveling details separately for speech and music parts:
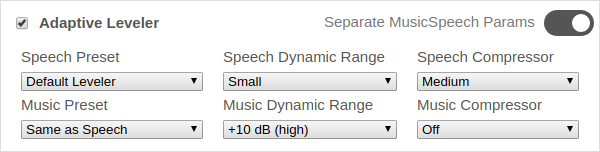
For dialog intelligibility improvements in films and TV, it is important that the speech/dialog level and loudness range is not too soft compared to the overall
programme level and
loudness range.
This parameter allows you to use more leveling in speech parts while keeping music and FX elements less processed.
Note: Speech, music and overall loudness and loudness range of your production are also displayed in our
Audio Processing Statistics!
Example Use Case:
Music live recordings or dynamic music mixes, where you want to amplify
all speakers (speech dynamic range should be small) but keep the dynamic range within and between music segments
(music dynamic range should be high).
Dialog intelligibility improvements for films and TV, without effecting music and FX elements.
Other Advanced Audio Algorithm Parameters
We also offer advanced audio parameters for our Noise, Hum Reduction and Global Loudness Normalization algorithms:
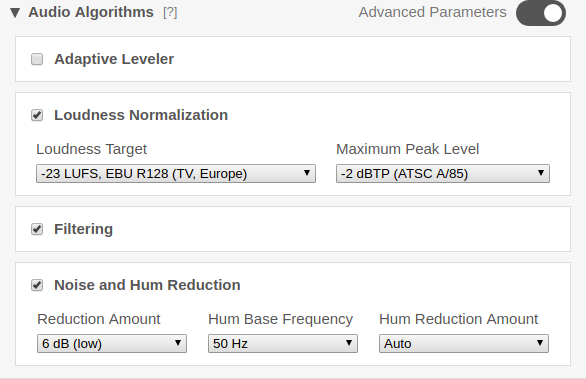
For more details, please see the Advanced Audio Algorithms Documentation.
Want to know more?
If you want to know more details about our advanced algorithm parameters (especially the leveler parameters), please listen to the
following podcast interview with Chris Curran (Podcast Engineering School):
Auphonic’s New Advanced Features, with Georg Holzmann – PES 108
Advanced Parameters Private Beta and Feedback
At the moment the advanced algorithm parameters are for beta users only.
This is to allow us to get user feedback, so we can change the
parameters to suit user needs.
Please let us know your case studies, if you need
any other algorithm parameters or if you have any questions!
Here are some private beta invitation codes:
jbwCVpLYrl 6zmLqq8o3z RXYIUbC6al QDmIZLuPKa JIrnGRZBgl SWQOWeZOBD ISeBCA9gTy w5FdsyhZVI qWAvANQ5mC twOjdHrit3 KwnL2Le6jB 63SE2V54KK G32AULFyaM 3H0CLYAwLU mp1GFNVZHr swzvEBRCVa rLcNJHUNZT CGGbL0O4q1 5o5dUjruJ9 hAggWBpGvj ykJ57cFQSe 0OHAD2u1Dx RG4wSYTLbf UcsSYI78Md Xedr3NPCgK mI8gd7eDvO 0Au4gpUDJB mYLkvKYz1C ukrKoW5hoy S34sraR0BU J2tlV0yNwX QwNdnStYD3 Zho9oZR2e9 jHdjgUq420 51zLbV09p4 c0cth0abCf 3iVBKHVKXU BK4kTbDQzt uTBEkMnSPv tg6cJtsMrZ BdB8gFyhRg wBsLHg90GG EYwxVUZJGp HLQ72b65uH NNd415ktFS JIm2eTkxMX EV2C5RAUXI a3iwbxWjKj X1AT7DCD7V y0AFIrWo5lWe are happy to send further invitation codes to all interested users - please do not hesitate to contact us!
If you have an invitation code, you can enter it here to activate the advanced audio algorithm parameters:
Auphonic Algorithm Parameters Private Beta Activation