If listeners find themselves using the volume up and down buttons a lot,
level differences within your podcast or audio file are too big.
In this article, we are discussing why audio
dynamic range processing
(or leveling) is more important than
loudness normalization,
why it depends on factors like the listening environment and the individual character of the content, and why the
loudness range
descriptor (LRA) is only reliable for speech programs.
 Photo by Alexey Ruban.
Photo by Alexey Ruban.
Why loudness normalization is not enough
Everybody who has lived in an apartment building knows the problem: you want to enjoy a movie late at night, but you're constantly on the edge - not only because of the thrilling story, but because your index finger is hovering over the volume down button of your remote. The next loud sound effect is going to come sooner rather than later, and you want to avoid waking up your neighbors with some gunshot sounds blasting from your TV.
In our previous post, we talked about the overall loudness of a production. While that's certainly important to keep in mind, the loudness target is only an average value, ignoring how much the loudness varies within a production. The loudness target of your movie might be in the ideal range, yet the level differences between a gunshot and someone whispering can still be enormous - having you turn the volume down for the former and up for the latter.
 While the average loudness might be perfect, level differences can lead to an unpleasant listening experience.
While the average loudness might be perfect, level differences can lead to an unpleasant listening experience.
Of course, this doesn't apply to movies alone. The image above shows a podcast or radio production. The loud section is music, the very quiet section just breathing, and the remaining sections are different voices.
To be clear, we're not saying that the above example is problematic per se. There are many situations, where a big difference in levels - a high
dynamic range - is justified: for instance, in a movie theater, optimized for listening and without any outside noise, or in classical music.
Also, if the dynamic range is too small, listening can be tiring.
But if you watch the same movie in an outdoor screening in the summer on a beach next to the crashing waves or in the middle of a noisy city, it can be tricky to hear the softer parts.
Spoken word usually has a smaller dynamic range, and if you produce your podcast for a target audience of train or car commuters, the dynamic range should be even smaller, adjusting for the listening situation.
Therefore, hitting the loudness target has less impact on the listening experience than level differences (dynamic range) within one file!
What makes a suitable dynamic range does not only depend on the listening environment, but also on the nature of the content itself.
If the dynamic range is too small, the audio can be tiring to listen to, whereas more variability in levels can make a program more interesting, but might not work in all environments, such as a noisy car.
Dynamic range experiment in a car
Wolfgang Rein, audio technician at SWR, a public broadcaster in Germany, did an experiment to test how drivers react to programs with different dynamic ranges. They monitored to what level drivers set the car stereo depending on speed (thus noise level) and audio dynamic range.
While the results are preliminary, it seems like drivers set the volume as low as possible so that they can still understand the content, but don't get distracted by loud sounds.
As drivers adjust the volume to the loudest voice in a program, they won't understand quieter speakers in content with a high dynamic range anymore. To some degree and for short periods of time, they can compensate by focusing more on the radio program, but over time that's tiring. Therefore, if the loudness varies too much, drivers tend to switch to another program rather than adjusting the volume.
Similar results have been found in a study conducted by NPR Labs and Towson University.
On the other hand, the perception was different in pure music programs. When drivers set the volume according to louder parts, they weren't able to hear softer segments or the beginning of a song very well. But that did not matter to them as much and didn't make them want to turn up the volume or switch the program.
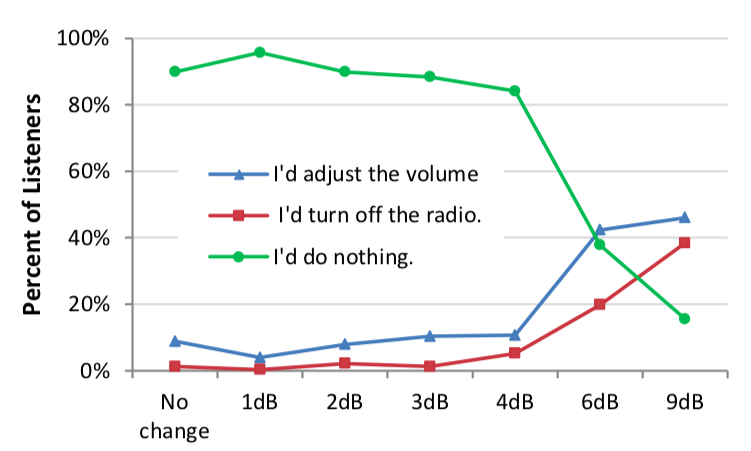 Listener's reaction in response to frequent loudness changes. (from John Kean, Eli Johnson, Dr. Ellyn Sheffield: Study of Audio Loudness Range for Consumers in Various Listening Modes and Ambient Noise Levels)
Listener's reaction in response to frequent loudness changes. (from John Kean, Eli Johnson, Dr. Ellyn Sheffield: Study of Audio Loudness Range for Consumers in Various Listening Modes and Ambient Noise Levels)
Loudness comfort zone
The reaction of drivers to variable loudness hints at something that BBC sound engineer Mike Thornton calls the loudness comfort zone.
Tests (...) have shown that if the short-term loudness stays within the "comfort zone" then the consumer doesn’t feel the need to reach for the remote control to adjust the volume.In a blog post, he highlights how the series Blue Planet 2 and Planet Earth 2 might not always have been the easiest to listen to. The graph below shows an excerpt with very loud music, followed by commentary just at the bottom of the green comfort zone. Thornton writes: "with the volume set at a level that was comfortable when the music was playing we couldn’t always hear the excellent commentary from Sir David Attenborough and had to resort to turning on the subtitles to be sure we knew what Sir David was saying!"
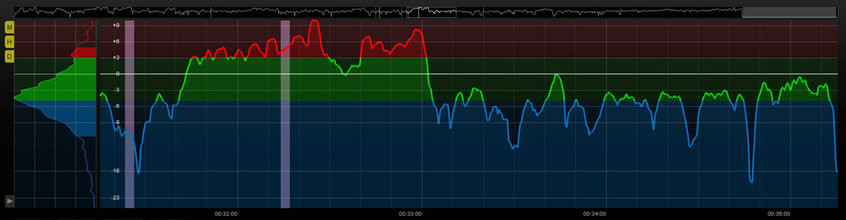 Planet Earth 2 Loudness Plot Excerpt. Colored green: comfort zone of +3 to -5LU around the loudness target. (from Mike Thornton: BBC Blue Planet 2 Latest Show In Firing Line For Sound Issues - Are They Right?)
Planet Earth 2 Loudness Plot Excerpt. Colored green: comfort zone of +3 to -5LU around the loudness target. (from Mike Thornton: BBC Blue Planet 2 Latest Show In Firing Line For Sound Issues - Are They Right?)
As already mentioned above, a good mix considers the maximum and minimum possible loudness in the target listening environment.
In a movie theater the loudness comfort zone is big (loudness can vary a lot), and loud music is part of the fun, while quiet scenes work just as well. The opposite was true in the aforementioned experiment with drivers, where the loudness comfort zone is much smaller and quiet voices are difficult to understand.
Hence, the loudness comfort zone determines how much dynamic range an audio signal can use in a specific listening environment.
How to measure dynamic range: LRA
When producing audio for various environments, it would be great to have a target value for dynamic range, (the difference between the smallest and largest signal values of an audio signal) as well. Then you could just set a dynamic range target, similarly to a loudness target.
Theoretically, the maximum possible dynamic range of a production is defined by the bit-depth of the audio format. A 16-bit recording can have a dynamic range of 96 dB; for 24-bit, it's 144 dB - which is well above the approx. 120 dB the human ear can handle. However, most of those bits are typically being used to get to a reasonable base volume. Picture a glass of water: you want it to be almost full, with some headroom so that it doesn't spill when there's a sudden movement, i.e. a bigger amplitude wave at the top.
Determining the dynamic range of a production is easier said than done, though.
It depends on which signals are included in the measurement: for example, if something like background music or breathing should be considered at all.
The currently preferred method for broadcasting is called Loudness Range, LRA. It is measured in Loudness Units (LU), and takes into account everything between the 10th and the 95th percentile of a loudness distribution, after an additional gating method. In other words, the loudest 5% and quietest 10% of the audio signal are being ignored. This way, quiet breathing or an occasional loud sound effect won't affect the measurement.
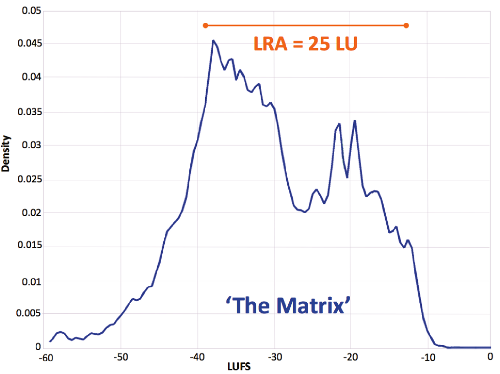 Loudness distribution and LRA for the film 'The Matrix'. Figure from EBU Tech Doc 3343 (p.13).
Loudness distribution and LRA for the film 'The Matrix'. Figure from EBU Tech Doc 3343 (p.13).
However, the main difficulty is which signals should be included in the loudness range measurement and which ones should be gated. This is unfortunately often very subjective and difficult to define with a purely statistical method like LRA.
Where LRA falls short
Therefore, only pure speech programs give reliable LRA values that are comparable!
For instance, a typical LRA for news programs is 3 LU; for talks and discussions 5 LU is common.
LRA values for features, radio dramas, movies or music very much depend on the individual character and might be in the range between 5 and 25 LU.
To further illustrate this, here are some typical LRA values, according to a paper by Thomas Lund (table 2):
| Program | Loudness Range |
|---|---|
| Matrix, full movie | 25.0 |
| NBC Interstitials, Jan. 2008, all together (3:30) | 9.4 |
| Friends Episode 16 | 6.6 |
| Speak Ref., Male, German, SQUAM Trk 54 | 6.2 |
| Speak Ref., Female, French, SQUAM Trk 51 | 4.8 |
| Speak Ref., Male, English, Sound Check | 3.3 |
| Wish You Were Here, Pink Floyd | 22.1 |
| Gilgamesh, Battle of Titans, Osaka Symph. | 19.7 |
| Don’t Cry For Me Arg., Sinead O’Conner | 13.7 |
| Beethoven Son in F, Op17, Kliegel & Tichman | 12.0 |
| Rock’n Roll Train, AC/DC | 6.0 |
| I.G.Y., Donald Fagen | 3.6 |
LRA values of music are very unpredictable as well.
For instance, Tom Frampton
measured the LRA
of songs in multiple genres, and the differences within each genre are quite big.
The ten pop songs that he analyzed varied in LRA between 3.7 and 12 LU, country songs between 3.6 and 14.9 LU. In the Electronic genre the individual LRAs were between 3.7 and 15.2 LU.
Please see the tables at the bottom of
his blog post for more details.
We at Auphonic also tried to base our Adaptive Leveler parameters on the LRA descriptor. Although it worked, it turned out that it is very difficult to set a loudness range target for diverse audio content, which does include speech, background sounds, music parts, etc. The results were not predictable and it was hard to find good target values. Therefore we developed our own algorithm to measure the dynamic range of audio signals.
In conclusion, LRA comparisons are only useful for productions with spoken word only
and the LRA value is therefore not applicable as a general dynamic range target value.
The more complex a production gets, the more difficult it is to make any judgment based on the LRA.
This is, because the definition of LRA is purely statistical. There's no smart measurement using classifiers that distinguish between music, speech, quiet breathing, background noises and other types of audio. One would need a more intelligent algorithm (as we use in our Adaptive Leveler), that knows which audio segments should be included and excluded from the measurement.
From theory to application: tools
Loudness and dynamic range clearly is a complicated topic. Luckily, there are tools that can help. To keep short-term loudness in range, a compressor can help control sudden changes in loudness - such as p-pops or consonants like t or k. To achieve a good mid-term loudness, i.e. a signal that doesn't go outside the comfort zone too much, a leveler is a good option. Or, just use a fader or manually adjust volume curves. And to make sure that separate productions sound consistent, loudness normalization is the way to go. We have covered all of this in-depth before.Looking at the audio from above again, with an adaptive leveler applied it looks like this:
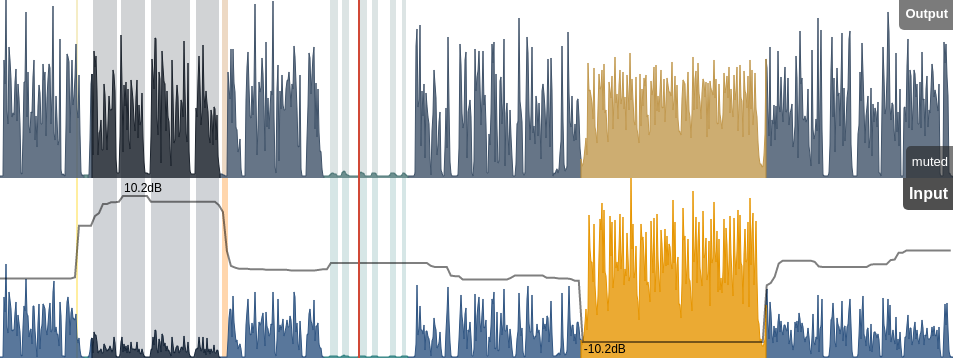 Leveler example. Output at the top, input with leveler envelope at the bottom.
Leveler example. Output at the top, input with leveler envelope at the bottom.
Now, the voices are evened out and the music is at a comfortable level, while the breathing has not been touched at all.
We recently extended Auphonic's adaptive leveler, so that it is now possible to customize the dynamic range - please see
adaptive leveler customization and
advanced multitrack audio algorithms.
If you wanted to increase the loudness comfort zone (or dynamic range) of the standard preset by 10 dB (or LU), for example, the envelope would look like this:
 Leveler with higher dynamic range, only touching sections with extremely low or extremely high loudness to fit into a specific loudness comfort zone.
Leveler with higher dynamic range, only touching sections with extremely low or extremely high loudness to fit into a specific loudness comfort zone.
When a production is done, our adaptive leveler uses classifiers to also calculate the integrated loudness and loudness range of dialog and music sections separately. This way it is possible to just compare the dialog LRA and loudness of complex productions.
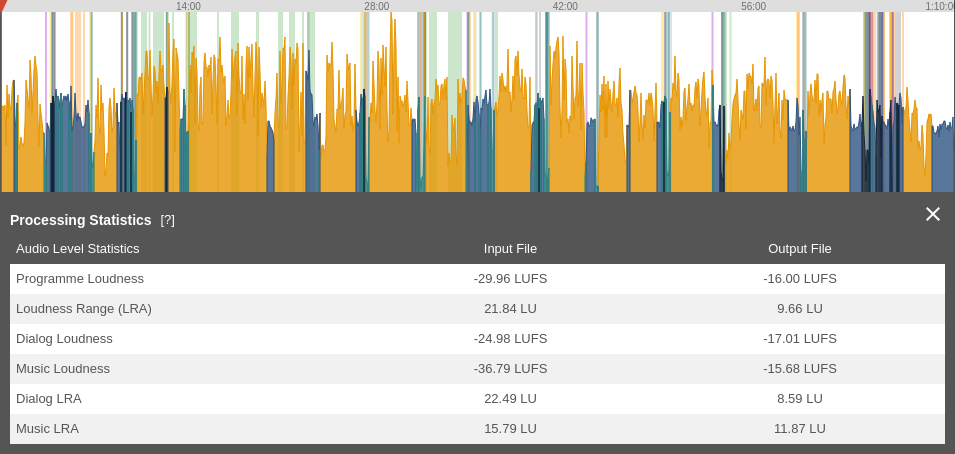 Assessing the LRA and loudness of dialog and music separately.
Assessing the LRA and loudness of dialog and music separately.
Conclusion
Getting audio dynamics right is not easy. Yet, it is an important thing to keep in mind, because focusing on loudness normalization alone is not enough. In fact, hitting the loudness target often has less impact on the listening experience than level differences, i.e. audio dynamics.
If the dynamic range is too small, the audio can be tiring to listen to, whereas a bigger dynamic range can make a program more interesting, but might not work in loud environments, such as a noisy train.
Therefore, a good mix adapts the audio dynamic range according to the target listening environment (different loudness comfort zones in cinema, at home, in a car) and according to the nature of the content (radio feature, movie, podcast, music, etc.).
Furthermore, because the definition of the loudness range / LRA is purely statistical, only speech programs give reliable LRA values that are comparable.
More "intelligent" algorithms are in development, which use classifiers
to decide which signals should be included and excluded from the dynamic range measurement.
If you understand German, take a look at our presentation about audio dynamic processing in podcasts for further information: