Last week we presented our new multitrack algorithms at the
Podlove Podcaster Workshop in Berlin.
Lot's of users asked us about a multitrack version of our system before - now it's
here and can be used!
We reworked all our algorithms and therefore start with a
private beta program for our long-term users and supporters.
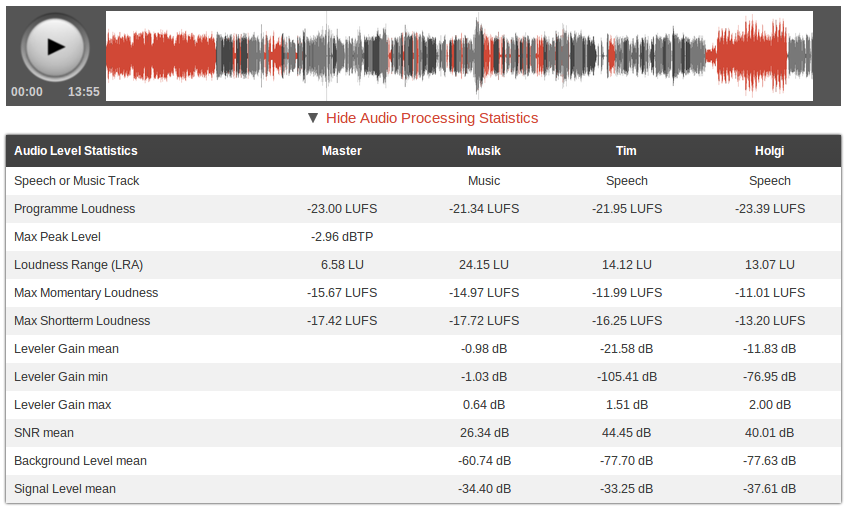 Audio statistics of an Auphonic production with multiple tracks.
Audio statistics of an Auphonic production with multiple tracks.
Music segments are displayed in red and the two speakers in gray and black.
UPDATE:
The Auphonic multitrack algorithms are now released officially:
Auphonic Multitrack Release.
What is Multitrack?
Auphonic is optimized to process stereo or mono audio files of a final mix.
However, many recordings consist of multiple tracks: speaker tracks from
multiple microphones, music tracks, remote speakers via skype, mumble, etc.
Until now, it was necessary to mixdown all tracks before processing the
final mix with Auphonic, otherwise the results could be problematic.
With our special multitrack algorithms, it's now possible to upload all individual tracks of your recordings. Auphonic will process all tracks and creates the final mixdown automatically. Using knowledge from signals of all individual tracks allows us to create a new class of multitrack audio algorithms and improves our results.
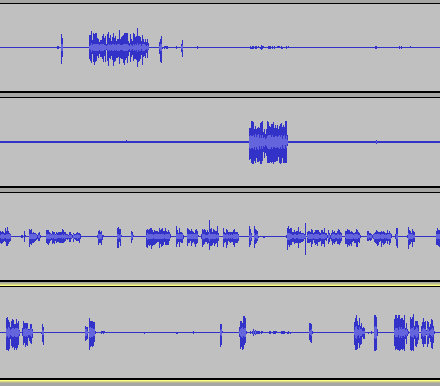 Audio recording with multiple tracks in Audacity.
Audio recording with multiple tracks in Audacity.
New Multitrack Audio Algorithms
Adaptive Noise Gate / Expander:
If you record audio from multiple microphones and mix all signals, the
noise of all tracks will also add up.
One way to decrease the amount of background noise is to use a
Noise Gate or Expander:
a gate decreases the volume of segments where a speaker is inactive (noise only),
but does not change segments where a speaker is active.
The Auphonic multitrack algorithms include an adaptive noise gate, which automatically
changes all parameters of the gate (threshold, ratio, sustain, etc.) according
to the current context.
Audio Crosstalk (Spill) Removal:
When recording an interview with multiple people using multiple microphones
in one room, the voice of speaker 1 will also be recorded with the microphone of speaker 2.
This Crosstalk / Spill
results in a reverb or echo-like effect in the final audio mixdown.
Furthermore it is very difficult to set the correct parameters of a noise gate,
because the crosstalk might be very loud.
In our multitrack algorithms we know exactly when and in which track a speaker is active
and can therefore remove the same signal (crosstalk) from all other tracks.
This results in a more direct signal and decreases ambience and reverb.
Algorithm Settings per Track:
It is now possible to activate
Noise and Hum Reduction or Filtering only
in one specific track, which was recorded e.g. in a bad environment.
Furthermore the Adaptive Leveler can produce better results, because we have
the combined knowledge of all tracks.
Track Activity Metadata:
As a side product, we can generate detailed metadata when which track or speaker
is active.
This might be used by a player for navigation (to next speaker), for visualization
or for speaker statistics - more about that in a later blog post.
A very basic visualization is already implemented in our web player, see multitrack stats screenshot.
Multitrack Productions and Presets
You must use our special multitrack production form to create a production with multiple audio files. Each track must have an identifier (a name) and has its own audio algorithm settings:
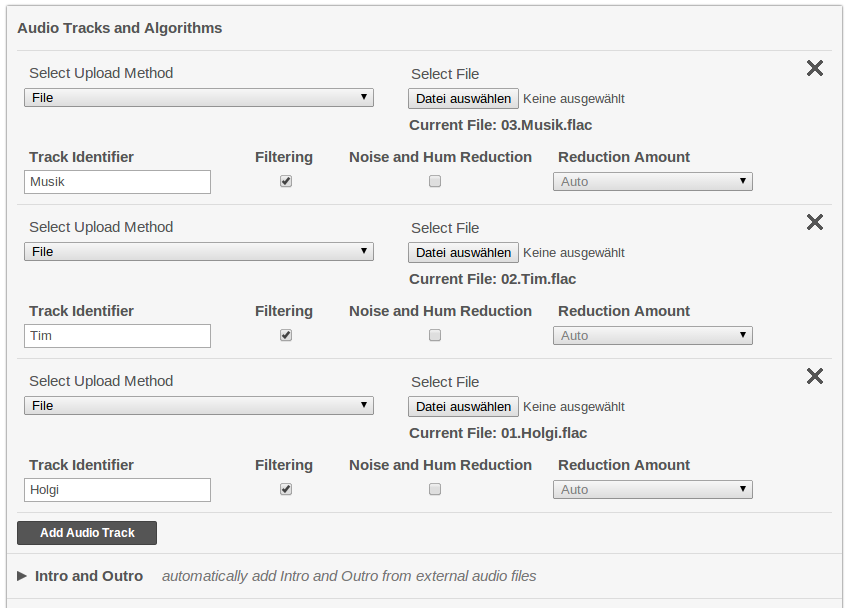
It is also possible to create multitrack presets with identifiers and algorithm settings for all tracks.
Note that standard presets do not work in multitrack productions!
Multitrack Presentation Video
If you understand German, you might watch the presentation video of the new multitrack features at the Podlove Podcasting Workshop 2014:
Auphonic Multitrack Private Beta Invite Codes
At the moment our multitrack algorithms are for beta users only. We are happy to send invitation codes to our long-term users and supportes (contact us).
If you receive an invitation code, you can enter it here to activate our multitrack algorithms:
Auphonic Multitrack Private Beta Activation
UPDATE:
Multitrack productions and presets are now fully integrated in our API:
Multitrack API Docs.
IMPORTANT:
Please note that these new algorithms are still in beta (there might be problems) and take a lot of processing time.
Listen to the results carefully and let us know if you experience any issues!