The Auphonic multitrack algorithms have been in Private Beta since May 2014 and after a long development process and many refinements, we are releasing them to the general public today!
UPDATE: More recent information about our multitrack algorithms can be found
here!
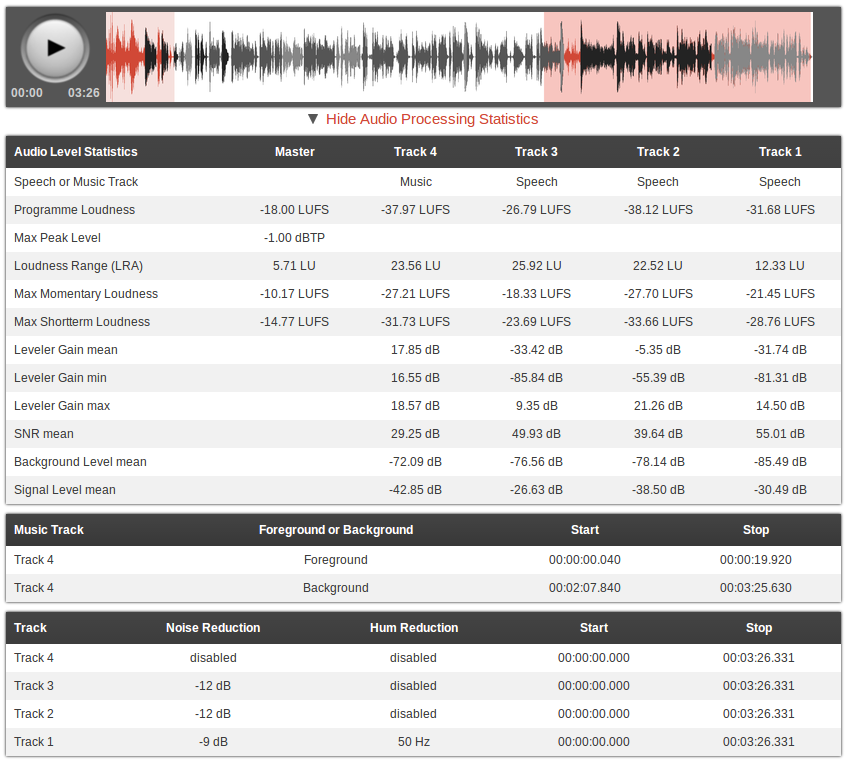 Audio statistics of an Auphonic production with multiple tracks.
Audio statistics of an Auphonic production with multiple tracks.
Music segments are displayed in red and the speakers in gray.
About Auphonic Multitrack
The Auphonic Multitrack Algorithms use multiple input audio tracks in one production: speech tracks recorded from multiple microphones, music tracks, remote speakers via phone, skype, etc. Auphonic processes all tracks individually as well as combined and creates the final mixdown automatically.
Using the knowledge from signals of all tracks allows us to produce much better results compared to our singletrack version:- The Multitrack Adaptive Leveler knows exactly which speaker is active in which track and can therefore produce a balanced loudness between tracks. Dynamic range compression is applied to speech only – music segments are kept as natural as possible.
- Noise profiles are extracted in individual tracks for automatic Multitrack Noise and Hum Reduction.
-
Adaptive Noise Gate / Expander:
If audio is recorded with multiple microphones and all signals are mixed, the noise of all tracks will add up as well. The Adaptive Noise Gate decreases the volume of segments where a speaker is inactive, but does not change segments where a speaker is active. This results in much less noise in the final mixdown. -
Crossgate:
If one records multiple people with multiple microphones in one room, the voice of speaker 1 will also be recorded in the microphone of speaker 2. This crosstalk (spill), a reverb or echo-like effect, can be removed by the Crossgate, because we know exactly when and in which track a speaker is active.
More information about our multitrack algorithms can be found in our previous blog post and in the audio examples below. As there are so many more details, we will write further in-depth blog posts about them in future.
Audio Examples
It is always difficult to explain audio algorithms, therefore we created some audio examples with detailed annotations about what is happening where.
Please click through the waveforms to see the annotations (written above the waveform) and compare files!
(If the examples are not working for you, open them in a recent Chrome or Firefox browser)
-
The first audio example consists of three speech and one music track from Operation Planlos. It demonstrates how the Multitrack Adaptive Leveler adjusts the loudness between speakers and music segments. Disturbing noises from inactive tracks are removed by the Adaptive Noise Gate.
-
Now an audio example with two female and one male speech track from the Einfacheinmal.de Podcast. The Adaptive Noise Gate is able to remove most of the background noises from other tracks, the rest is eliminated by our Noise Reduction algorithms.
-
The next example consists of one music, one male speech and two female speech tracks from Bits Of Berlin and demonstrates the combination of all algorithms. The first segment in the music track (the intro) is classified as foreground, the second segment (at the end) as background music and therefore automatically gets a lower level during the mixdown.
-
In the last example, recorded in a very reverberant room at a conference by Das Sendezentrum, it is possible to hear the crosstalk (spill) between the three active microphones and how the Crossgate is able to decrease ambience and reverb.
Background, Foreground Tracks and Automatic Ducking
The parameter Fore/Background controls, if a track should be in foreground, in background or ducked:

Use Ducking to automatically reduce the level of this track if speakers in other tracks are active. This is useful for intros/outros or for music, which should be softer if someone is speaking.
If Fore/Background is set to Auto, Auphonic automatically decides which parts of your track should be in foreground or background:- Speech tracks will always be in foreground.
- In music tracks, all segments (e.g. songs, intros, etc.) are classified as background or foreground segments (see screenshot above) and are mixed to the production accordingly.
The automatic fore/background classification will work most of the time.
However, in special productions, like a very complex background music, a background speech
track, or if you do the ducking manually in your audio editor, you can force the track to be in foreground or in background.
Practical Tips
- Please try to put all speakers into a separate track and music parts into another track as well! Music segments are classified as background or foreground segments (see Fore/Background) and are mixed to your production accordingly.
- We do not change the stereo panorama of your individual tracks – please adjust it in your audio editor before the upload – mono tracks are mixed in centered. However, we might add an additional parameter for panning in future.
- If you want to keep the ambience of your recordings, try to deactive the Adaptive Noise Gate or Crossgate.
- See also our Multitrack Best Practice!
For Paying Users
UPDATE:
The Auphonic multitrack algorithms are now
free for short productions up to 20min!
The Auphonic multitrack algorithms are now released for paying users only, because they need much more processing time on our servers and they are more complicated to use
.
However, feel free to try these algorithms and if you don't like the results, just use the
refund button to get your credits back!