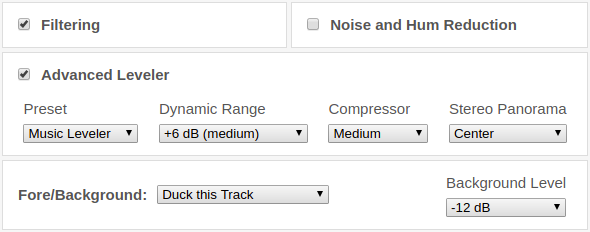
You run a podcast hosting service (or similar) and want to integrate it as publishing target within Auphonic? That's now possible using the Auphonic API.
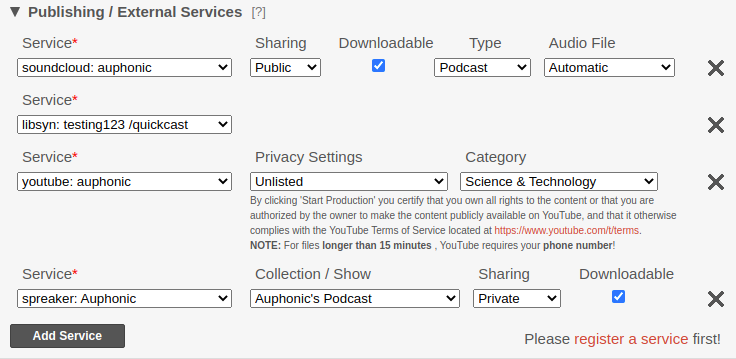 Publishing / External Services section of a Production: integrate your service as an additional target.
Publishing / External Services section of a Production: integrate your service as an additional target.
(click to enlarge)
You can now connect your custom service or app (podcast hosting company, audio publishing platform, video tool, file service, etc.) as an External Service to Auphonic.
Then all Auphonic users will see your service at our External Services Page and will be able to reference it in any Production or ...




 Photo by
Photo by  Resist the loudness target war! (Photo by
Resist the loudness target war! (Photo by